剑指Offer系列
分治
从前序与中序遍历序列构造二叉树
前序遍历:节点按照[根|左|右]排序
中序遍历:节点按照[左|根|右]排序
根据这两个性质,我们可以得出以下结论:
前序遍历的首节点为根节点
node中序遍历中搜索根节点
node的值,得到其索引,在索引左边的,即为左子树,在索引右边的即为右子树根据中序遍历的划分,又可以将前序遍历中的
[根节点|左子树|右子树]划分出来(在这里引用 Krahets )的图片,笔记中也有所参考
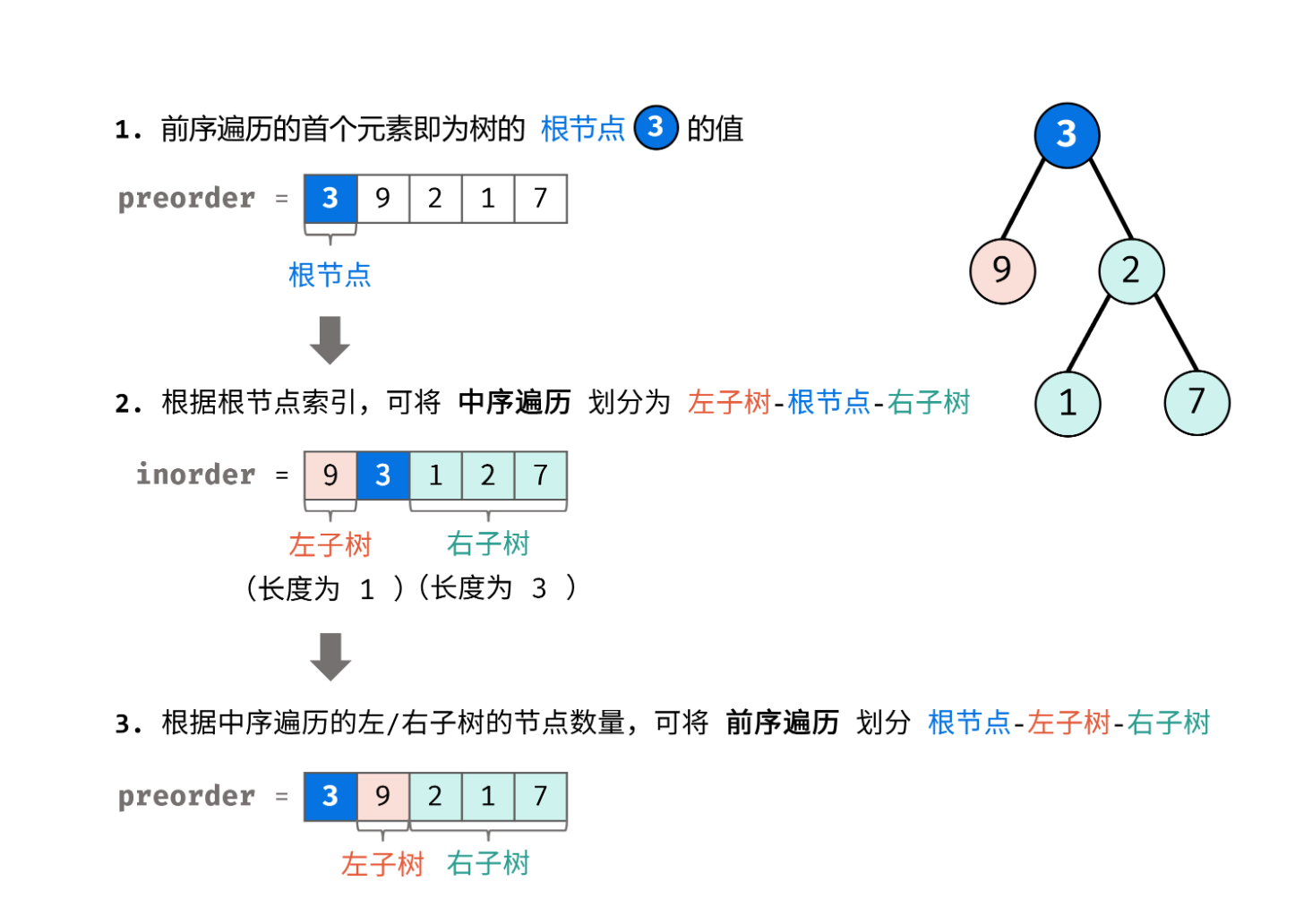
通过以上步骤,我们可以确定最主要的三个节点,==树的根节点, 左子树的根节点,右子树的根节点==
根据分治的思想,对于左右子树,我们也可以利用以上的方法划分子树的左右子树以及根节点
算法过程
参数:根节点在前序遍历中的索引root,当前根节点的左子树在中序遍历中的左边界left,右子树在中序遍历中的右边界right
退出条件:当left > right的时候,代表以及越过了叶子节点,此时返回 null
在二叉树的中序遍历中,对于任何一个节点,其左子树的所有节点的索引都会在它之前,右子树的所有节点的索引都会在它之后。因此,如果在中序遍历中,左边界
left大于右边界right,那么这就意味着已经没有节点可以遍历了,也就是说已经越过了叶子节点。
如果在中序遍历中,左边界
left等于右边界right,那么这意味着当前子树只有一个节点。这是因为left和right分别代表了当前子树的左右边界,如果left = right,那么说明当前子树只有一个节点,也就是叶子节点。
递推过程:
建立根节点
node: 节点值为preorder[root]划分左右子树:利用根节点在中序遍历中的位置,可以划分左右子树,此时需要用到值与索引,考虑使用
HashMap进行映射。查找到根节点在中序遍历inorder中的索引i构建左右子树:递归构建
左子树:
- 根节点索引 :
root + 1 - 中序遍历左边界 :
left - 中序遍历右边界 :
i - 1
右子树:
- 根节点索引 :
root + i - left + 1 - 中序遍历左边界 :
i+1 - 中序遍历右边界 :
right
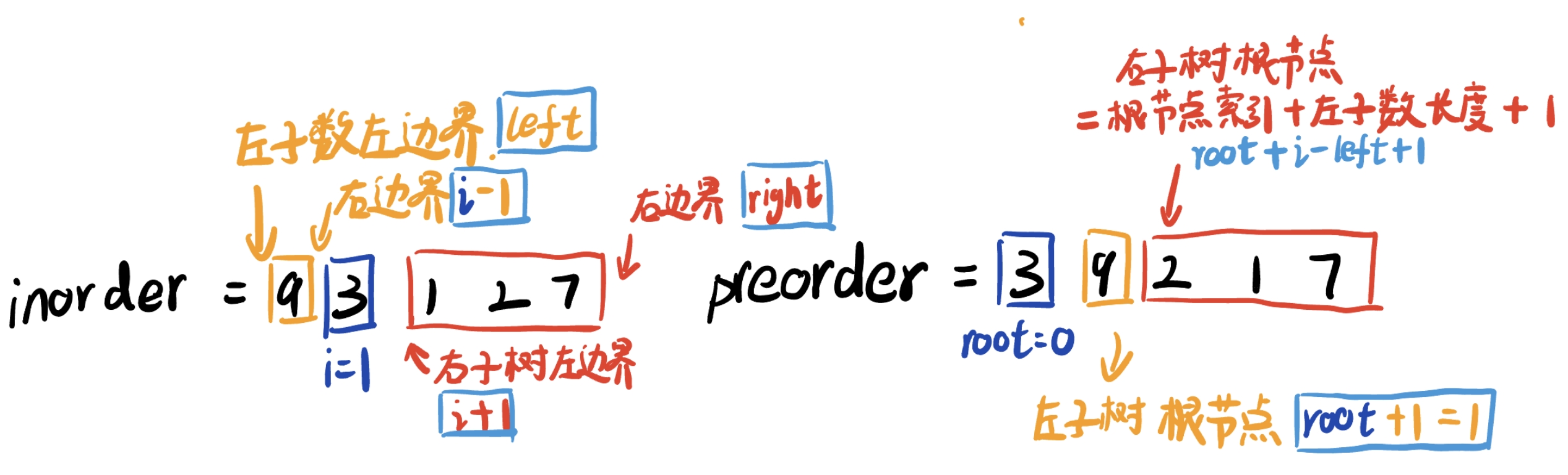
- 根节点索引 :
返回值:回溯返回node,作为上一层递归中的根节点的左 / 右子节点
代码示例
1 | class Solution { |
平衡二叉树
平衡二叉树 是指该树所有节点的左右子树的深度相差不超过 1
给定一个二叉树,如何判断它是否是平衡二叉树?
理解平衡二叉树的定义,我们可以明白,平衡二叉树的每个节点的左右子树的高度的绝对值不超过1。一个树是平衡二叉树的话,里面的所有子树也是平衡二叉树。我们就可以用递归的方式去判断。判断其每一颗树是不是平衡二叉树。
自顶向下的递归
从最顶上的节点开始,判断其左右子树的高度,取最大值,再加上自己本身的高度 1 ,即为当前节点的高度。如果是空节点,则高度为 0 。
我们可以定义一个函数,去计算当前节点的高度,这里也需要用到递归的思想
1 | public int height(TreeNode node){ |
现在我们有了计算节点高度的函数,需要判断二叉树是否平衡。前面说到,平衡二叉树的所有子树都是平衡二叉树。我们采用前序遍历,即对于当前遍历到的节点,首先计算其左右子树的高度,如果左右子树的高度差不超过 1,再分别递归遍历左右子节点,判断左子树和右子树是否平衡。这就是自顶向下的递归过程。
1 | class Solution { |
翻转二叉树
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点
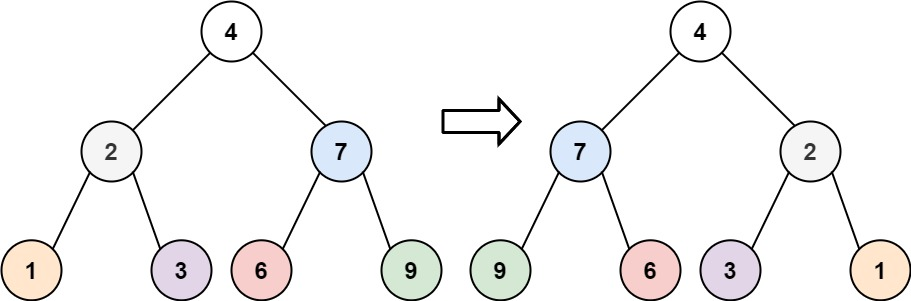
翻转,顾名思义,将该二叉树的所有子树进行节点的翻转
方法一:递归
根据翻转的定义,我们可以递归遍历二叉树,交换每一个节点的左右子节点,将二叉树进行翻转。
终止条件:当节点
root为空的时候,即已经越过了子节点,返回null。递归过程:
初始化一个节点
temp,用于暂存root的左子节点开始递归右子节点,将其返回值作为
root的左子节点开始递归左子节点,将其返回值作为
root的右子节点为什么要暂存root的左子节点?
在递归右子节点的代码执行完毕后,root.left 值已经发生了变化,此时再用该值会造成错误
1 | class Solution { |
方法二:栈
我们可以利用栈,遍历树的所有节点,并交换每个node节点的左右子节点
有点类似二叉树的层序遍历,不过我们在这不是输出,而是进行交换
初始化: 栈(或队列),本文用栈,并加入根节点
root。循环交换: 当栈
stack为空时跳出。出栈: 记为
node。添加子节点: 将
node左和右子节点入栈。交换: 交换
node的左 / 右子节点。
返回值: 返回根节点
root。
1 | class Solution { |
动态规划
打家劫舍
题目:你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
看到这个题目,首先想到的就是动态规划的方法去解决,创建一个dp数组,用来存储当前所需要的值。
首先创建一个动态规划列表dp,dp[i]代表前i+1个房子在满足题干条件下所能偷窃到的最高金额。
对于每个房子,我们都有偷或不偷的两个选项,我们可以先对dp的前几个值进行设定。
第一间房子,对应的dp[0],在我们的设定下,dp[i]代表前 i+1 个房子的最高金额,所以第一间房子的金额就是对应的数组金额。而第二间房子,我们如果偷了第一间,则不能偷第二间,但如果第二间房子的金额大于第一间房子呢?这时候的数组dp[1]中就应该直接存放第二间房子的金额,而不偷第一间。这就是我们对动态规划列表前两项的初始化。
接下来我们又可以思考,第三间呢?对于第三间,我们也有两个选项,偷第一间和第三间 或者 只偷第二间,这时候这会涉及到我们对应的动态规划方程了。对于第三间之后的每间房子,都会有两种情况,这时候我们就要选取其中的最大值。本质上来说,也是对这个房间偷或者不偷的抉择。
1 | dp[i] = Math.max(dp[i-1],nums[i]+dp[i-2]); |
如果不偷,那么当前数组中的值就会跟dp中前一个房间的值一样,如果偷,那就是用当前房间的金额加上dp数组中上上个房间对应的最高金额。比较两个的大小,来决定对于当前房间的能偷窃到的最大金额。
1 | class Solution { |
最大子数组和
题目:给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
**子数组 ** 是数组中的一个连续部分。
经典的动态规划题目
首先定义一个动态规划列表dp[],dp[i]代表以元素nums[i]为结尾的连续子数组最大和
这里有一个最关键的点
dp[i]中必须包含元素nums[i],如果不包含,那么不满足题干连续子数组的要求,在转移方程中我们也可以看出来- 如果执行到某个元素例如
nums[i],导致之前的和dp[i-1]已经小于了nums[i],则说明我们的子数组需要进行更新了。前面的数据开始产生负影响。
如果dp[i-1]<=0,说明dp[i-1]对dp[i]产生的是负贡献,即dp[i-1]+nums[i]甚至不如nums[i]本身大。以此我们可以得出转移的代码逻辑。
1 | dp[i] = Math.max(nums[i],dp[i-1]+nums[i]); |
最终解决方案
1 | class Solution { |
最长递增子序列
题目:给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列
dp[i] 的值代表 nums 以 nums[i]结尾的最长子序列长度
设 *j∈[0,i)*,考虑每轮计算新 dp[i] 时,遍历 [0,i) 列表区间,做以下判断:
当
nums[i]>nums[j]时: nums[i] 可以接在 nums[j] 之后(此题要求严格递增),此情况下最长上升子序列长度为dp[j]+1;当
nums[i]<=nums[j]时: nums[i] 无法接在 nums[j] 之后,此情况上升子序列不成立,跳过。上述所有 1. 情况 下计算出的
dp[j]+1的最大值,为直到 i 的最长上升子序列长度(即dp[i])。实现方式为遍历 j 时,每轮执行dp[i]=max(dp[i],dp[j]+1)。转移方程:
dp[i] = max(dp[i], dp[j] + 1) for j in [0, i)
初始状态:dp[i] 所有元素置 1,含义是每个元素都至少可以单独成为子序列,此时长度都为 1。
1 | class Solution { |
栈和队列
字符串解码
题目:给定一个经过编码的字符串,返回它解码后的字符串。
编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例 1:
1 | 输入:s = "3[a]2[bc]" |
示例 2:
1 | 输入:s = "3[a2[c]]" |
这题的难点在于,括号内会存在嵌套括号,所以我们需要的是从内向外生成拼接的字符串,例如示例2,需要先将 2[c] 生成,与外面的 a 拼接,再用 3 去生成最终的字符串。这样的思想符合栈先入后出的性质,所以我们用栈解决
首先我们需要去遍历给出的 String 类型变量,由题目可知,我们可能遇到的不同类型的字符分别是:
- int类型
[]- 字符类型
在遇到不同的类型的时候,我们也需要进行不同的处理
首先我们考虑遇到数字类型该怎么处理,由题目可知,数字类型关联的是我们生成字符串的个数,在字符串的拼接的时候,会用到相应的数字。由于我们是从内向外生成字符串,所以我们需要一个数字类型的Stack去保存我们的数字,同时,对应的数字还有可能是多位数,我们在处理数字的时候,也需要考虑如何对多位数进行处理,将最终的数字字符转换成
mul,用于倍数计算如果是字母,我们只需要在构建的 StringBuilder 对象
res的末尾添加该字符即可如果是
[,说明我们现在最外层的探寻已经结束,需要将当前计算出来的mul和生成的res进行入栈处理,由于最外层的遍历已经结束,同时也需要将这两个数据置空,进行第二层遍历计算的操作如果是
],例如第一次遇到],说明我们最内层的遍历已经结束,s = "3[a2[c]]",我们用这个进行举例,当第一次遇到],也就是最内层的2[c],此时,我们应该将当前的res也就是c,用于生成字符串。由于我们每次在不同层的遍历都会重新设置并转换
mul,并将其入栈,所以我们现在应该将栈中的数据进行出栈操作,栈是先入后出的,所以出栈的就是对应的倍数,在这也就是2,利用循环将其拼接成一个新的字符串,cc。拼接成cc后,我们应该再将字符串栈中的数据进行出栈,与当前的字符串再次拼接,也就是将a和cc进行拼接的操作,变成一个新的字符串acc,此时,最内层的字符串已经生成了,用于之后外层字符串的生成。
1 | class Solution { |
滑动窗口
找到字符串中所有字母异位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
异位词 指由相同字母重排列形成的字符串(包括相同的字符串)。
示例 1:
1 | 输入: s = "cbaebabacd", p = "abc" |
经典的滑动窗口
我们可以利用HashMap的特性,将每个char类型的变量作为键,出现的次数作为值,放入一个hashmap中。
而我们滑动的窗口,也需要一个hashMap去对应,随着窗口的滑动,该hashmap的内容也会随之变化,而我们只需要在每次变化后,去比较两个map是否相等,如果相等,则说明是异位词,如果不相等,则说明不是。
1 | class Solution { |
我们这里的处理,将第一次窗口直接初始化,然后在for循环中开头就进行判断,这样子方便了我们的操作,但是会有一个问题,最后一次的判断,无法在for循环中进行,所以我们需要将最后一次的判断也挪动到for循环外面进行。
 wechat
wechat alipay
alipay