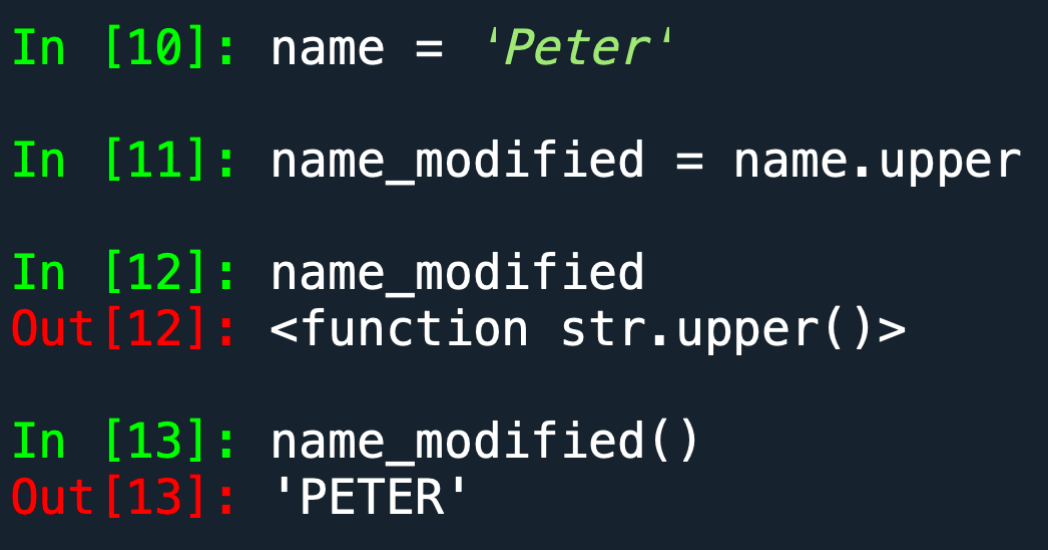
SMA-w2_1
Variables(变量)
1 | message="Hello World!" |
变量的名字可以用数字,字母或者下划线,但是不能用数字进行开头。同时不能用Python的关键词或者函数(keywords or functions)
输出语句
1 | print("Hello World") |
If you need to use variables in strings,
you could use f-strings (f means format)
1 | a = "LQY" |
运行结果
1 | Hello LQY Vera |
Tabs and Newlines
You can use \t or \n to improve the format of the print output
1 | print("\tHello") |
运行结果:
1 | Hello |
1 | print("\nVera") |
运行结果
1 | Vera |
Remove whitespace
Remove extra whitespace (temporarily) in strings: rstrip(), lstrip(), strip()
1 | name = ' LQY Vera ' |
运行结果
1 | LQY Vera |
根据运行结果可以发现,运行strip(),并不会直接将原始变量的前后空格去除,而只是临时去除,第二次输出变量的时候,前后空格依然存在,所以只有将去除空格后的变量去赋值,才可以保存变量
1 | name = ' LQY Vera ' |
1 | # 运行结果 |
Numbers
Integers 类型,最基础的整数
与数字类型相关的运算符,+, -, *, /, **,** 代表平方,例如3 ** 2的结果是9。(在操作符前后加上空格可以提高代码的可读性)
多重赋值:Multiple assignment: x, y, z = 1, 2, 3 。在python中,你可以利用多重赋值来减少代码的行数,这一句代码的意思是给x赋值为1,y赋值为2,z赋值为3。
Numbers with a decimal point is called a float (eg, 3.0).
带了小数点的数字,被称为浮点数(3.0),也就是小数
计算机在内存中以一种特定的方式存储数字,它们通常必须将某些数字(如π)四舍五入为接近但不完全相等的值。因为计算机内部是使用二进制存储,表达的数字范围有限,一般很长的小数都无法表达出完全相等的值。
Str() function
此函数可以帮助你让不同类型的数据能够兼容
str()可以将数字转换为字符串
当你想同时将数字类型和字符串类型赋值给一个变量的时候,python会报错
1 | age = 3 |
1 | age = 3 |
Q & A
- Q: What does the empty parentheses at the end of a method do?
- 问:方法末尾的空括号有什么作用?
- A: When you define a function, you need to allow it to receive parameters (we will talk about it later in the course), and you will use parentheses for that purpose. Methods are similar to functions and follow that tradition, but for a different reason. Without them, the method wouldn’t actually be called (see examples in next slide).
- 答:当你定义一个函数时,你需要允许它接收参数(我们将在课程后面讨论这个),你将使用括号来实现这个目的。方法类似于函数,并遵循这一传统,但出于不同的原因。如果没有它们,方法实际上不会被调用(请参阅下一张幻灯片中的示例)。
Q: What is the difference in calling a function and calling a method
问:调用函数和调用方法有什么区别?
Functions are not associated with any object, and they operate on the data you pass to them as arguments. eg. str(age) in the previous example about str() function;
函数不与任何对象关联,它们操作你传递给它们的数据作为参数。例如,在关于 str() 函数的前面示例中的 str(age);
Methods are associated with the objects. eg. name.title()
方法与对象关联。例如,name.title();
Did you notice that the order is different?
Bool
- Boolean data have two values:
True, False - For numbers,
Bool()function returns False for zero values and True for non-zero values - For strings,
Bool()returns False for empty strings and True for non-empty strings - This might be useful when your programme has to make selections in coding
- You can use
type()function to check the data type
布尔值
- 布尔数据有两个值:
True(真)和False(假) - 对于数字,
Bool()函数返回零值为False,非零值为True - 对于字符串,
Bool()返回空字符串为False,非空字符串为True - 在编程中,这可能会在程序需要进行选择时很有用
- 你可以使用
type()函数来检查数据类型
举个例子
1 | # 提示用户输入信息 |
运行结果
1 | 请输入一些信息:你好 |
在这个例子中,用户输入信息后,程序将检查该信息是否为空字符串。如果用户输入了非空字符串,布尔值为True,程序会打印出用户输入的信息;如果用户没有输入任何内容(即空字符串),布尔值为False,程序会提示用户没有输入信息。
Common operators
● arithmetic: % (return remainder), // (return integral result)
● relational: ==, !=, <, >, <=, >=
● logical: and, or, not
● membership: in, not in
● identity: is, is not (try 2 is 20 and see what python will return) (similar to ==, but is check if two variables pointing to the same object
常见的运算符
算术运算符:
%(返回余数),//(返回整数结果)1
2
3
4
5
6print(f"4 % 2 = {4%2}")
print(f"4 % 3 = {4%3}")
# 6//3 返回的是整数
print(f"6 // 3 = {6//3}")
# 6/3 返回的是小数,也就是float
print(f"6 / 3 = {6/3}")运行结果
1
2
3
44 % 2 = 0
4 % 3 = 1
6 // 3 = 2
6 / 3 = 2.0关系运算符:
==, !=, <, >, <=, >=1
2
3
4print(f"1==1:{1==1}")
print(f"1!=1:{1!=1}")
print(f"1>=0:{1>=0}")
print(f"1!=0:{1!=0}")运行结果
1
2
3
41==1:True
1!=1:False
1>=0:True
1!=0:True逻辑运算符:
and, or, not1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 1 代表true 0 代表false
# 以下涉及逻辑表达式
print(f"真 and 假:{1 and 0}")
print(f"真 and 真:{1 and 1}")
print(f"假 and 假:{0 and 0}")
print(f"真 or 假:{1 or 0}")
print(f"真 or 真:{1 or 1}")
print(f"假 or 假:{0 or 0}")
print(f"not 假:{not 0}")
print(f"not 真:{not 1}")
print(f"not 假:{not 0}")
# 总结: and 有一个为假,结果为假;
# or 有一个为真,结果为真
# not 即为取反运行结果
1
2
3
4
5
6
7
8
9真 and 假:0
真 and 真:1
假 and 假:0
真 or 假:1
真 or 真:1
假 or 假:0
not 假:True
not 真:False
not 假:True成员运算符:
in, not in1
2
3
4list = ['a','b','c','d']
print('a' in list)
print('a' not in list)
print('o' in list)运行结果
1
2
3True
False
False身份运算符:is, is not(尝试 2 is 20,看看 Python 会返回什么)(类似于 ==,但 is 检查两个变量是否指向同一个对象)
1 | print(2 is 20) |

这里报错是由于int类型不建议用 is 去比较,在这主要看False
“同一个对象”通常指的是内存中的同一块区域被多个变量引用。当你创建一个对象(例如一个整数、字符串、列表等),Python会为该对象分配一块内存,并将变量关联到该内存地址。如果两个变量引用的内存地址相同,则这两个变量指向的是同一个对象。
1 | X = 30 |
在这里,x和y都指向内存中存储整数值 30 的同一块区域。因此,我们可以说x和y引用了同一个对象。
Comments
Use # to indicate the start of a comment, and Python would ignore the line
You should use comments in your codes to make them easier to understand
注释
使用 # 来表示注释的开始,Python 将忽略该行
你应该在你的代码中使用注释来使其更易于理解
1
2
3# 你好,这是一段注释,Python并不会读到我,只有你会
x = 3
print(x)1
2# 运行结果
3
Input()
- The input() function pauses your program and waits for the user to enter some text.
- The input by the user will be assigned to a variable.
- Exercise: ask the user to input two integers, then divide the first one by the second one, and return the remainder. # you may need to use function
int()
Input()
- input() 函数会暂停你的程序,并等待用户输入一些文本。
- 用户输入的内容将被赋值给一个变量。
- 练习:要求用户输入两个整数,然后将第一个数除以第二个数,并返回余数。你可能需要使用
int()函数。
1 | x = input("x = ") |
运行结果
1 | x = 4 |
Basic operations on strings
- Use + to combine two strings
- Select one character of a string, use index (starts from 0).
- Use len() to find the length
- Select part of the string, use index in the format of [start: end: step]
字符串的基本操作
- 使用
+来连接两个字符串 - 选择字符串的一个字符,使用索引(从0开始)。
- 使用
len()函数来找到字符串的长度 - 选择字符串的一部分,使用索引的格式
[start: end: step]
Algorithm
- An algorithm is a step-by-step procedure for solving problems.
- An algorithm shows the sequence of tasks. Some tasks can be divided further into subtasks.
- Sequence, iteration, selection are the common elements in algorithm
- Algorithms can be represented by flow diagrams or pseudocode
算法
- 算法是解决问题的逐步过程。
- 算法显示任务的顺序。某些任务可以进一步分解为子任务。
- 顺序、迭代、选择是算法中常见的元素。
- 算法可以用流程图或伪代码表示。
SMA-w3_1
Lists
What are lists
Lists (together with dictionary, tuples etc.) are a basic data structure in Python
- 列表(与字典、元组等一起)是Python中的基本数据结构
A list is a collection of items (you could include different data types such as letters, numbers, strings in the same list)
- 列表是项的集合(你可以在同一个列表中包含不同的数据类型,比如字母、数字、字符串)
Square brackets [ ] and commas
- 方括号
[ ]和逗号
- 方括号
Assign the values to a list:
words = ['spam', 'eggs', 100, 1234]- 将值赋给列表:
words = ['spam', 'eggs', 100, 1234]
- 将值赋给列表:
Better to use plural form for the list variable
- 最好使用复数形式来命名列表变量
Exercise: Define a list variable called friends and assign values to it
- 练习:定义一个名为 friends 的列表变量,并为其赋值
1
2
3
4
5friends = ['Lixc','Laiym','Huangyt','Niu']
print(friends)
# 运行结果:
# ['Lixc', 'Laiym', 'Huangyt', 'Niu']
Index positions: use index to fetch individual values of a list (similar to strings, the index positions start at 0), eg. print(bicycles[0])
- 索引位置:使用索引来获取列表的单个值(类似于字符串,索引位置从0开始),例如 print(bicycles[0])
Exercise: print out the 1st element in your friends list
练习:打印出你的 friends 列表中的第一个元素
1
2
3
4
5friends = ['Lixc','Laiym','Huangyt','Niu']
print(friends[0])
# 运行结果
# Lixc
Sometimes it is easier to use negative index to locate an element from the end
- 有时使用负索引更容易从末尾定位元素
print(friends[-1])1
2
3
4
5friends = ['Lixc','Laiym','Huangyt','Niu']
print(friends[-1])
# 运行结果
# NiuYou can select a portion of the elements in a list by giving two index positions (with or without steps). However the item with the end index won’t be included in the portion.
可以通过给出两个索引位置(带有或不带有步长)来选择列表中的一部分元素。然而,以 end 索引结尾的元素不会包含在所选部分中。
1
2
3
4
5friends = ['Lixc','Laiym','Huangyt','Niu']
print(friends[1:3]) # 不带步长
# 运行结果
# ['Laiym', 'Huangyt']列表中的索引是从0开始的。
上述代码中
[1:3]代表从列表中,索引为1的位置开始,索引为3的位置结束,但不包括索引为3的元素。也就是friends[1]&friends[2]1
2
3
4
5friends = ['Lixc','Laiym','Huangyt','Niu']
print(friends[0:3:2]) # 带步长
# 运行结果
# ['Lixc', 'Huangyt']0:代表从列表索引为0的位置开始
3:代表列表索引为3的位置结束(也不包括3)
2:代表一次走2步
我们可以想象现在你的两只脚站在索引为0的位置,先输出这个位置的元素,左脚走一步,到了索引1,右脚再走一步,到了索引2的位置,现在你已经走了两步了,将索引2的元素输出。后面你又走了两步,但已经走出了我们想要结束的位置,所以没有东西输出了。
The order of selection stays the same for negative index positions unless you use negative steps.
除非你使用负步长,否则选择顺序保持不变。
1
2
3
4
5friends = ['Lixc','Laiym','Huangyt','Niu']
print(friends[-1:-4:-1])
# 运行结果
# ['Niu', 'Huangyt', 'Laiym']方法思想与上述类似,不过现在从索引-1开始,从’Niu’开始,倒着走。
You can use individual values from a list as you would do with a variable
你可以像使用变量一样使用列表中的单个值
1
2
3
4
5friends = ['Lixc','Laiym','Huangyt','Niu']
print(f"Hello {friends[3].format()}")
# 运行结果
# Hello Niu
list() function. You can create an empty list or quickly change the letters of a string to a list by using list() function
- list() 函数。你可以通过使用 list() 函数创建一个空列表,或者快速将字符串的字母更改为列表。
a = list()ora = list(‘Hello’)1
2
3
4
5a = list("hello")
print(a[0])
# 运行结果
# h
Copy a List
A list can be copied by using = operator, but the problem is that they both reference to the same list object.
- 一个列表可以通过使用
=操作符进行复制,但问题是它们都引用同一个列表对象。
- 一个列表可以通过使用
Try the following command: a=[1, 2, 3], b=a, b[0]=4, print(a)
尝试以下命令:
a=[1, 2, 3], b=a, b[0]=4, print(a)1
2
3
4
5
6
7
8
9a = [1,2,3]
b = a
b[0] = 4
print(f"b跟a是同一个对象吗?:{b is a}")
print(a)
# 运行结果
# b跟a是同一个对象吗?:True
# [4, 2, 3]- is 用于判断是否是同一个对象
A right way of copying a list is to use a copy() method b=a.copy()
复制列表的正确方法是使用
copy()方法:b=a.copy()1
2
3
4
5
6
7
8
9
10
11a = [1,2,3]
b = a.copy()
b[0] = 4
print(f"b跟a是同一个对象吗?:{b is a}")
print(f"b:{b}")
print(f"a:{a}")
# 运行结果
# b跟a是同一个对象吗?:False
# b:[4, 2, 3]
# a:[1, 2, 3]
Another right way is to use slicing
b=a[:]- 另一种正确的方法是使用切片
b=a[:]
- 另一种正确的方法是使用切片
Editing the elements
Modifying elements. You just replace it with a new value
修改元素。只需用新值替换它即可。
Adding elements. Use append() to add an element to the end of a list. Only one value can be added at a time. For example: friends.append(‘John’).
- 添加元素。使用
append()将一个元素添加到列表的末尾。每次只能添加一个值。例如:friends.append('John')。
- 添加元素。使用
In programming, you may need to define an empty list and then keep adding the values you want
- 在编程中,您可能需要定义一个空列表,然后不断添加所需的值。
motorbike = [], motorbike.append(‘Toyota’)
1
2motorbike = []
motorbike.append('Toyota')Insert an element. Use
insert()method.friends.insert(1, ‘Paul’)- 插入元素。使用
insert()方法。例如:friends.insert(1, 'Paul')。
- 插入元素。使用
Remove elements (for example, you may need to delete a username in a list).Use del command. del friends[1]
- 删除元素(例如,您可能需要从列表中删除一个用户名)。使用
del命令。例如:del friends[1]。
- 删除元素(例如,您可能需要从列表中删除一个用户名)。使用
Remove with pop() method. The deleted value can be assigned to another variable so that you can use it again.
- 使用
pop()方法删除。被删除的值可以赋给另一个变量,以便稍后使用。 friend_left = friends.pop()- You can pop a specific element of the list.
friends.pop(1) - 您可以从列表中弹出特定的元素。例如:
friends.pop(1)。
- 使用
Remove by value. You can remove an element by using the remove() method if you don’t know the index position.
根据值删除。如果您不知道索引位置,可以使用
remove()方法删除一个元素。1
2
3
4
5
6
7friends = ['潇洒哥','黑大帅']
theManDel = '潇洒哥'
friends.remove(theManDel)
print(friends)
# 运行结果
# ['黑大帅']上面代码删除了名为
‘潇洒哥’的元素
Two lists can be combined by using ’ + ‘
两个列表可以通过使用
+运算符来合并1
2
3
4
5
6friends = ['潇洒哥','黑大帅']
frineds2 = ['GGBond','小呆呆']
print(friends+frineds2)
# 运行结果
# ['潇洒哥', '黑大帅', 'GGBond', '小呆呆']
Organising a list
组织列表
You may want to change the original order of a list (function of sorted, only temporarily unless you assign the value to the variable)
您可能想要改变列表的原始顺序(使用
sorted函数,只在临时性地改变,除非您将值分配给变量)1
2
3
4
5
6
7friends = ['a','c','b','d','e']
print(sorted(friends))
print(friends)
# 运行结果
# ['a', 'b', 'c', 'd', 'e']
# ['a', 'c', 'b', 'd', 'e']
Sorting a list permanently. Use
sort()method永久排序一个列表。使用
sort()方法friends.sort()
1
2
3
4
5
6friends = ['a','c','b','d','e']
friends.sort()
print(friends)
# 运行结果
# ['a', 'b', 'c', 'd', 'e']
But you need to make sure the data types are consistent (alphabetically or by the value of numbers)
- 但您需要确保数据类型是一致的(按字母顺序或按数字的值)
Sort in reverse order (mind the capital T).
按照相反的顺序排序(注意大写 T)
friends.sort(reverse=True)
1
2
3
4
5
6friends = ['a','c','b','d','e']
friends.sort(reverse=True)
print(friends)
# 运行结果
# ['e', 'd', 'c', 'b', 'a']
Reverse the original order. Use
reverse()method.反转原始顺序。使用
reverse()方法friends.reverse()
1
2
3
4
5
6friends = ['a','c','b','d','e']
friends.reverse()
print(friends)
# 运行结果
# ['e', 'd', 'c', 'b', 'a']
Finding the length
use len() function to find the length.
- 使用
len()函数来找到列表的长度。 len(friends)
- 使用
Index errors.
- Sometimes it might be better to use negative index to avoid index errors
- 有时使用负索引可能更好,以避免索引错误。
为什么说有时候使用负索引会更好?
- 在处理列表时,有时候我们想要访问列表末尾的元素,但是不知道列表的确切长度。使用负索引可以让我们从列表的末尾开始计数,这样就可以避免由于列表长度不确定而导致的索引错误。因此,当我们不确定列表长度时,使用负索引是一种更加安全和可靠的方法。
Other operations
Find the index position of an element. Use index() method. friends.index(‘Peter’)
- 查找元素的索引位置。使用index()方法。
friends.index('Peter')
- 查找元素的索引位置。使用index()方法。
Check if a list contains a particular value.
‘Peter’ in friends- 检查列表是否包含特定值。
'Peter' in friends
- 检查列表是否包含特定值。
Count the times a value appears in a list.
friends.count(‘Peter’)- 计算一个值在列表中出现的次数。
friends.count('Peter')
1
2
3
4
5
6
7
8
9
10
11phones = ['小米','华为','OPPO','vivo','apple','小米']
print(phones.index('小米')) # 只会找到第一个出现的元素的索引
print('小米' in phones)
print('xiaomi' in phones)
print(phones.count('小米'))
# 运行结果
# 0
# True
# False
# 2- 计算一个值在列表中出现的次数。
Naming variables
- Variable names should be as descriptive as possible
- 变量名应尽可能描述性强
- Shorter names are easier to type and spell, while longer names could easily be misspelt.
- 较短的名称更容易输入和拼写,而较长的名称容易拼写错误。
- Naming conventions: a commonly used convention is to use camel case (e.g. FirstName or firstName)
- 命名约定:常用的约定之一是使用驼峰命名法(例如
FirstName或firstName)
- 命名约定:常用的约定之一是使用驼峰命名法(例如
- Another is to use an underscore (
first_name)- 另一种是使用下划线(
first_name)
- 另一种是使用下划线(
SMA-w4_1
For loops
You use For loops to perform the same task multiple times. This can be efficient when you need to run through all the entries in a list
- 可以使用For循环多次执行相同的任务。当你需要遍历列表中的所有条目时,这是有效的
For example, you need to print out all the cities in a list
例如,你需要打印出列表中的所有城市
1
2
3
4
5
6
7cities = ['ZhuHai','NanChang','HangZhou']
for city in cities:
print(city)
# 运行结果
# ZhuHai
# NanChang
# HangZhou
Don’t forget the colon; correct indentation is important
- 不要忘记冒号;正确的缩进很重要。
Python takes a value from the list, assign the value to a variable, and process the variable. Fetch the next value from the list and repeat the process until all the items have been processed
- Python从列表中取出一个值,将该值赋给一个变量,并处理该变量。然后从列表中获取下一个值并重复这个过程,直到所有项目都被处理完。
Exercise: Define a list of customers (some of the names are not capitalised), print out a new year greeting in the following format:
练习:定义一个客户名单(其中一些名称没有大写),以以下格式打印新年祝福:
Dear Peter,
- Happy new year to you!
Dear Paul,
Happy new year to you!
1
2
3friends = ['Vera','Maple','Tony']
for friend in friends:
print(f"Dear {friend.title()},\n\t Happer new year!\n")1
2
3
4
5
6
7
8
9# 运行结果
Dear Vera,
Happer new year!
Dear Maple,
Happer new year!
Dear Tony,
Happer new year!
All indented lines will be processed for every item of the list.
- 所有缩进的行将针对列表的每个项目进行处理。
Add another line to the end of the programme with and without indentation, understand the difference
在程序的末尾添加另一行,一行带缩进,一行不带缩进,理解它们之间的区别。
1
2
3
4friends = ['Vera','Maple','Tony']
for friend in friends:
print(f"Dear {friend.title()},\n\t Happer new year!")
print("\t这个是带了缩进,存在在for循环中\n")1
2
3
4
5
6
7
8
9
10
11
12# 运行结果
Dear Vera,
Happer new year!
这个是带了缩进,存在在for循环中
Dear Maple,
Happer new year!
这个是带了缩进,存在在for循环中
Dear Tony,
Happer new year!
这个是带了缩进,存在在for循环中1
2
3
4friends = ['Vera','Maple','Tony']
for friend in friends:
print(f"Dear {friend.title()},\n\t Happer new year!")
print("\t这个是不带缩进,不存在在for循环中\n")1
2
3
4
5
6
7
8# 运行结果
Dear Vera,
Happer new year!
Dear Maple,
Happer new year!
Dear Tony,
Happer new year!
这个是不带缩进,不存在在for循环中总的来说,python中for循环是注重缩进的格式的,在for循环中如果是同一缩进,则说明其在循环体内。
Numerical lists
You may need to generate a list with numerical values to keep track of the position of some items.
- 你可能需要生成一个包含数字值的列表来跟踪某些项目的位置。
You can use range() function to achieve that. In range(1,5), 1 and 5 represents the start and finishing number respectively (but 5 is not included)
你可以使用range()函数来实现这一点。在range(1,5)中,1和5分别表示起始和结束的数字(但5不包括在内)
1
2for value in range(1,5):
print(value)1
2
3
4
5# 运行结果
1
2
3
4
If only one parameter is assigned a value, then the numerical list will start from 0
- 如果只给一个参数赋值,那么数字列表将从0开始。
The data type generated is not a list, but can be transformed into a list by using list() function. For example: list(range(1, 5))
- 生成的数据类型不是列表,但可以使用list()函数将其转换为列表。例如:list(range(1, 5))
Steps can be added as a parameter into the range() function
- 步长可以作为参数添加到range()函数中。
list(range(1, 11, 2))
1
2l = list(range(1, 11, 2))
print(l)1
2# 运行结果
[1, 3, 5, 7, 9]Exercise 1: Define a numerical list with even numbers 2-20 (inclusive) as its elements
- 练习1:定义一个数字列表,其中包含2-20(包括)之间的偶数作为其元素。
Exercise 2: use For loop to print out the cubed result of each number (hint: use **3 to cube individual number)
练习2:使用For循环打印出每个数字的立方结果(提示:使用**3来对单个数字进行立方)。
1
2
3
4
5
6
7
8
9
10num_ls = range(2,21,2)
print("Print out the range directly:")
print(num_ls)
print("Print out the individual elements:")
for num in num_ls:
print(num)
print("Print out the cubed elements:")
for num in num_ls:
print(num**3)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# 运行结果
Print out the range directly:
range(2, 21, 2)
Print out the individual elements:
2
4
6
8
10
12
14
16
18
20
Print out the cubed elements:
8
64
216
512
1000
1728
2744
4096
5832
8000
List comprehensions. A list comprehension combines the for loop and the creation of new elements into one line
列表推导式。列表推导式将for循环和新元素的创建合并到一行中。
1
print([2*x for x in range(6)])
1
2# 运行结果
[0, 2, 4, 6, 8, 10]
Exercise: what results will you get from [m + n for m in ‘ABC’ for n in ‘XYZ’]
练习:对于 [m + n for m in ‘ABC’ for n in ‘XYZ’],你会得到什么结果?
1
print([m + n for m in 'ABC' for n in 'XYZ'])
1
2# 运行结果
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
Functions of min(), max(), sum() for lists of numbers
对于数字列表的 min()、max()、sum() 函数
1
2
3
4
5l = list(range(6))
print(f"l:{l}")
print(f"max of l:{max(l)}")
print(f"min of l:{min(l)}")
print(f"sum of l:{sum(l)}")1
2
3
4
5# 运行结果
l:[0, 1, 2, 3, 4, 5]
max of l:5
min of l:0
sum of l:15
Nested list
- 嵌套列表
Use
s[2][1].title()to get the data of Shenzhen使用
s[2][1].title()来获取深圳的数据1
2
3
4
5p = ['Zhuhai','shenzhen']
s = ['Beijing','Guangzhou',p]
print(s)
print(s[2],s[2][1])
print(s[2][1].title())1
2
3
4# 运行结果
['Beijing', 'Guangzhou', ['Zhuhai', 'shenzhen']]
['Zhuhai', 'shenzhen'] shenzhen
Shenzhen
Slicing
- Slice a list by specifying two index positions.
friends[0:3]. Similar to range function, the element at the finishing index position won’t be included.- 通过指定两个索引位置来对列表进行切片。
friends[0:3]。类似于range函数,结束索引位置处的元素不会被包括在内
- 通过指定两个索引位置来对列表进行切片。
- When a index is omitted, the list will start from the beginning or finishing at the end of the list. e.g.
friends[:3]orfriends[0:]- 当一个索引被省略时,列表将从开头开始或在列表末尾结束。例如,
friends[:3]或friends[0:]
- 当一个索引被省略时,列表将从开头开始或在列表末尾结束。例如,
- When both indices are omitted, all elements in a list will be selected. e.g.
friends[:]- 当两个索引都被省略时,列表中的所有元素都将被选择。例如,
friends[:]
- 当两个索引都被省略时,列表中的所有元素都将被选择。例如,
- Negative indices can be used in slicing. e.g.
list[-3:]- 可以在切片中使用负索引。例如,
list[-3:]
- 可以在切片中使用负索引。例如,
- Sliced list can be used in for loops, e.g. for
value in values[:3]- 切片后的列表可以在for循环中使用,例如,
for value in values[:3]
- 切片后的列表可以在for循环中使用,例如,
Exercise
Define an empty list of courses. Ask a student to enter 5 courses they prefer to study this semester and add them to the list
定义一个空的课程列表。要求一个学生输入他们本学期喜欢学习的5门课程,并将它们添加到列表中。
1 | # 定义一个空的课程列表 |
1 | # 运行结果 |
Tuples
- Tuples are similar to lists, but their elements can not be changed. This can be useful in avoiding unintentional modification
- 元组与列表类似,但它们的元素不可更改。这在避免意外修改时非常有用
- The syntax of defining a tuple is also similar to defining a list, but use parentheses instead of square brackets. For example, old_friends = (‘Peter’, ‘John’)
- 定义元组的语法也类似于定义列表,但使用圆括号而不是方括号。例如,old_friends = (‘Peter’, ‘John’)
- Tuples can be used in for loops as well
- 元组也可以在for循环中使用。
- You can reassign the variable of a tuple
- 你可以重新分配元组的变量。
元组和列表之间的主要区别在于它们的可变性:
- 可变性:
- 元组(Tuple)是不可变的数据类型,一旦创建后,其元素不能被修改、添加或删除。
- 列表(List)是可变的数据类型,可以修改、添加或删除其中的元素。
- 定义语法:
- 元组使用圆括号
()来定义,例如:my_tuple = (1, 2, 3) - 列表使用方括号
[]来定义,例如:my_list = [1, 2, 3]
- 元组使用圆括号
下面是一个例子来说明两者的区别:
1 | # 定义一个元组和一个列表 |
Style
Don’t mix tabs and spaces for indentation. It would be difficult to spot the problem when the indentation is not done correctly.
- 不要混合使用制表符和空格进行缩进。当缩进不正确时,很难发现问题
Control the length of each line so that they can be read more easily. Use
\at the end and then start a new line控制每行的长度,使其更容易阅读。在行尾使用 \ 然后开始新的一行
for x in range( \ 5): print(x)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
- 这里只是举个使用`\`的例子,上面程序是可以正常运行的
- You can add blank lines to group different parts of your programme
- 你可以添加空白行来分组你程序的不同部分
- Use comments
- 使用注释
### Exercise
- Define a list of universities including (United International College, Hong Kong Baptist University, Beijing Normal University). Then define another list of divisions (Division of Humanities and Social Sciences, Division of Science, Division of Engineering)
- 定义一个包括(联合国际学院、香港浸会大学、北京师范大学)的大学列表。然后定义另一个包括(人文与社会科学部、理学部、工程部)的部门列表
- Combine the values in these two lists and add them to another list. The element in the new list should be like ‘Division of Humanities and Social Sciences at Beijing Normal University’
- 将这两个列表中的值组合起来,添加到另一个列表中。新列表中的元素应该类似于 ‘北京师范大学的人文与社会科学部
```python
uni = ['Beijing Normal university','United International College']
div = ['Division of Humanities and Social Sciences',\
'Divison of Science','Divison of Engineering']
new_ls = []
for u in uni:
# 嵌套for循环
for d in div:
new_ls.append(d+' at '+ u)
for division in new_ls:
print(division)
运行结果
1
2
3
4
5
6Division of Humanities and Social Sciences at Beijing Normal university
Divison of Science at Beijing Normal university
Divison of Engineering at Beijing Normal university
Division of Humanities and Social Sciences at United International College
Divison of Science at United International College
Divison of Engineering at United International College
SMA-w5_1
Conditional tests
A if statement allows you to examine a set of conditions and respond appropriately
if语句允许您检查一组条件并适当地做出响应
1
2
3
4
5
6cities = ['zhuhai','shenzhen','Guangzhou']
for city in cities:
if city=='zhuhai':
print(city.upper())
else:
print(city.title())运行结果
1
2
3ZHUHAI
Shenzhen
Guangzhou可以利用
==检查相等性,但请注意,测试相等性是区分大小写的,比如您想判断,当前的城市是不是zhuhai,可能会由于大小写的错误导致判断失败。我们利用上面的列表,执行以下语句1
print(cities[0]=='Zhuhai')
运行结果
1
False
这是由于列表中的
zhuhai首字母是小写,导致判断为不相等,但其实他也是珠海不是吗?我们该如何避免这种问题?可以使用
.upper()或者.lower()来解决这个问题,它会将所有的字母都改成大写或者小写,不会有大小写不匹配的问题了
Checking for inequality use
!=检查不等式使用
!=1
2
3
4
5
6university = "UIC"
uni = input("Enter your school:")
if uni != university:
print("You are not our student")
else:
print("Hi~UICer")上述代码有一个问题,就是当你输入除了全大写的
UIC以外,都会判断有误,你能想到如何避免这个错误吗?是的,答案就在上面。1
2
3
4
5
6university = "UIC"
uni = input("Enter your school:")
if uni.upper() != university:
print("You are not our student")
else:
print("Hi~UICer")运行结果
1
2Enter your school:Uic
Hi~UICer
For numerical comparisons, you can use ==, <=, >= etc.
- 对于数字比较,可以使用
==,<=,>=等
- 对于数字比较,可以使用
Checking multiple conditions, you can use and, or
检查多个条件,可以使用
and,or1
2
3
4
5
6cities = ['Shenzhen','Guangzhou','Zhuhai']
if cities[0].lower()=='shenzhen' and \
cities[1].lower()=='guangzhou':
print("This group is from Guangdong")
else:
print("This group is form Guangxi")运行结果
1
This group is from Guangdong
Checking whether a value is in a list, use
in- 检查值是否在列表中,请使用
in
- 检查值是否在列表中,请使用
Sometimes you may want to use not in
有时你可能希望使用
not in1
2
3
4
5
6friends=['Ming','Hong','Huang']
name = input("Please enter your name:")
if name.title() not in friends:
print("Who are you?")
else:
print(f"Hi~{name.title()}")运行结果
1
2Please enter your name:ming
Hi~Ming
What will the result be like in the following codes?
以下代码的结果将是什么样的?
1
2name = 'ming'
print(name == 'ming')运行结果
1
true
If conditional statements
- Simple if statements. If the conditional test evaluates to
True, Python executes the following code, if evaluates toFalse, Python simply ignores the following code.- 简单的if语句。如果条件测试评估为
True,则Python执行以下代码;如果评估为False,则Python简单地忽略以下代码
- 简单的if语句。如果条件测试评估为
if-elsestatements.if-elsesyntax allows you to take one action when a condition is met and a different action in all other cases.if-else语句。if-else语法允许您在满足条件时采取一种操作,在所有其他情况下采取不同的操作
- You could use nested
if-elsestatements- 您可以使用嵌套的
if-else语句
- 您可以使用嵌套的
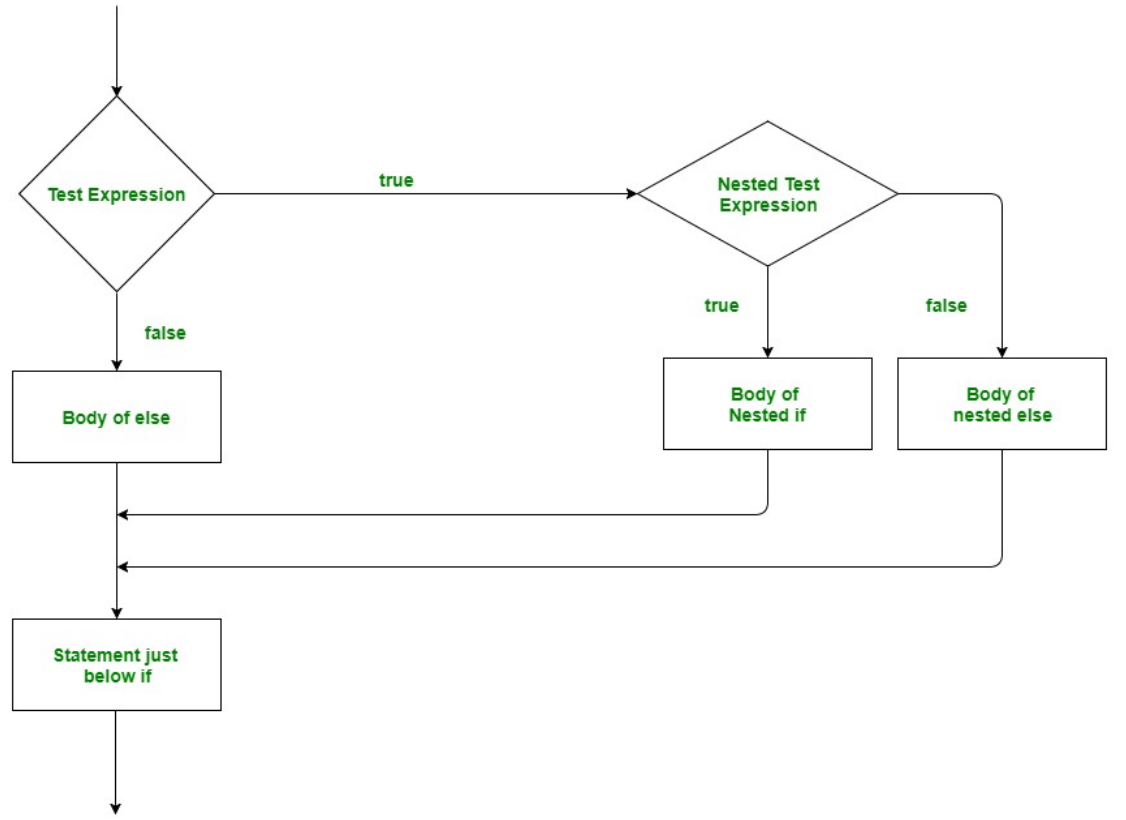
Nested if conditional statements
嵌套的if条件语句
1 | if (condition1): |
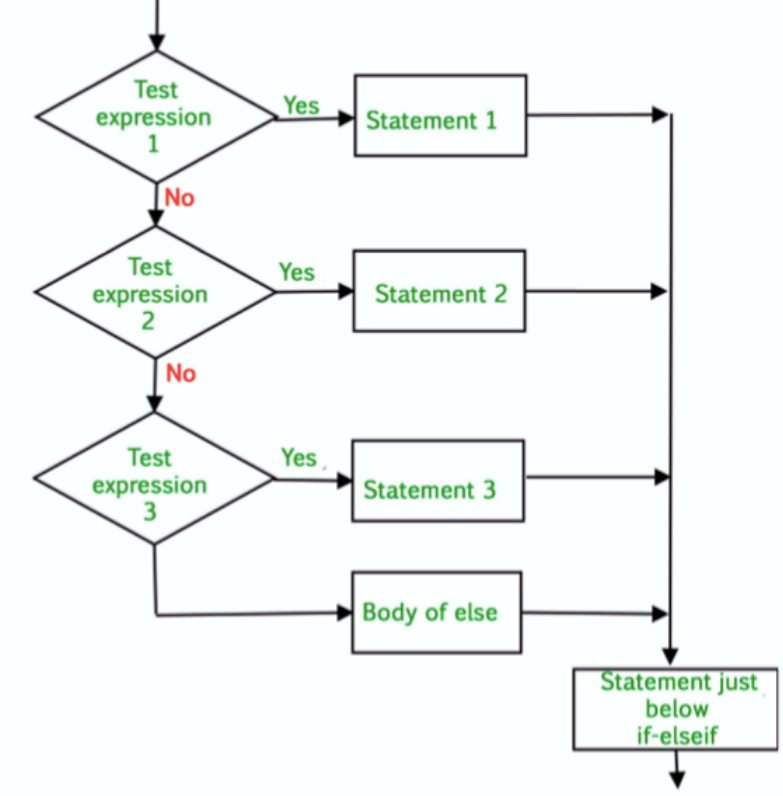
if-elif-else. Test more than two possible alternatives. It runs each conditional test in order until one passes. When a test passes, the code following that test is executed and Python skips the rest of the tests.if-elif-else。测试多于两个可能的替代方案。它按顺序运行每个条件测试,直到一个通过为止。当测试通过时,执行该测试后面的代码,Python跳过其余的测试
You can omit the else block in if-elif-else chain. It might be clearer to use an additional elif statement with a specific condition
- 您可以在
if-elif-else链中省略else块。使用具有特定条件的额外elif语句可能更清晰
- 您可以在
if-elif-else flowchart
For example, you can ask university students in different years to choose certain courses by using
if-elif-else1
2
3
4
5
6
7
8
9
10
11year = int(input("请输入您的年级(1/2/3/4):"))
if year == 1:
print("请选择以下课程:英语入门、数学基础、计算机入门")
elif year == 2:
print("请选择以下课程:英语进阶、数学拓展、数据结构与算法")
elif year == 3:
print("请选择以下课程:专业英语、高等数学、数据库原理")
elif year == 4:
print("请选择以下课程:毕业论文准备、实习课程")
else:
print("请输入正确的年级!")
Exercise
Write a programme to print out the price for passengers at different ages. Rule: full price is 30; those who are 60 years old and above can have 50% discount; for those who are 18 years old and above but less than 60, if they are students, they can have 40% off, if not, they pay full price; for those who are 6 years old but less than 18, they can get 40% off; for children under 6 years old, it is free
编写一个程序,根据乘客的不同年龄打印出价格。规则如下:全价为30;60岁及以上的人可以享受50%的折扣;18岁及以上但不满60岁的人,如果他们是学生,可以享受40%的折扣,否则他们需支付全价;6岁及以上但不满18岁的人,可以享受40%的折扣;6岁以下的儿童可以免费乘车
1
2
3
4
5
6
7
8
9
10
11
12
13age = input("Please enter your age:")
price = 30
if int(age) >=60:
price = price * 0.5
elif int(age) >= 18:
student = input("Are you a student?(Y/N)")
if student.upper()=='Y':
price = price * 0.6
elif int(age) >= 6:
price = price * 0.6
else:
price = 0
print("Your ticket price is:"+str(price))
Potential issues
When conditional tests are carried out, you need to make sure all possibilities are considered. Otherwise, there might be logical mistakes.
- 当进行条件测试时,您需要确保考虑到所有可能性。否则,可能会出现逻辑错误
The
elseblock matches any situations not matched byiforeliftest, this could be a source of problems. If you know what specific condition you are testing, it is better to useelifblock and omit theelseblock.else块匹配未被if或elif测试匹配的任何情况,这可能是问题的根源。如果您知道您正在测试的具体条件,最好使用elif块并省略else块。
For if-elif-else chain, as soon as one test passes, it will skip the rest of the test. If you need to check all of the conditions (more than one condition could be True), you should use a series of if statements without elif or else blocks.
- 对于
if-elif-else链,一旦一个测试通过,它将跳过剩余的测试。如果您需要检查所有条件(可能有多个条件为True),您应该使用一系列不带elif或else块的if语句。
- 对于
e.g, if someone wants to order a cup of tea, you may need to check if they want to add sugar, add milk, and if they want to sit in the store or take it away. (see core book, p83)
例如,如果有人想要点一杯茶,您可能需要检查他们是否想要加糖、加牛奶,以及他们是否想要在店内或外带。(参见核心书,第83页)
1
2
3
4
5
6
7
8
9request = ['sugger','milk']
if 'sugger' in request:
print("Adding sugger")
if 'solt' in request:
print("Adding solt")
if 'milk' in request:
print("Adding milk")
print("This is your coffee")运行结果
1
2
3Adding sugger
Adding mil
This is your coffee
Ex. for loop and conditionals
Display the options of drink, and remind customers to choose different options (remember that the latest value for the variable of option is 4)
显示饮料选项,并提醒顾客选择不同的选项(请记住,选项变量的最新值为4)
1
2
3
4
5
6
7
8
9
10
11items = ['Tea','Coke','Coffee']
option = 1
for choice in items:
print(str(option)+'.'+choice)
option = option + 1;
print(str(option)+'.Quit')
order = input("Please enter your choice of drink:")
if order and int(order) != option:
print("Please pay by cash or Alipay")
else:
print("no choice")以上为ppt中源代码,有缺陷,由于if语句只判断不等于option时候,输出支付语句,在本题中,此时option为4,也就是quit选项。可是如果输入5,5不等于4,依然是输出支付语句。
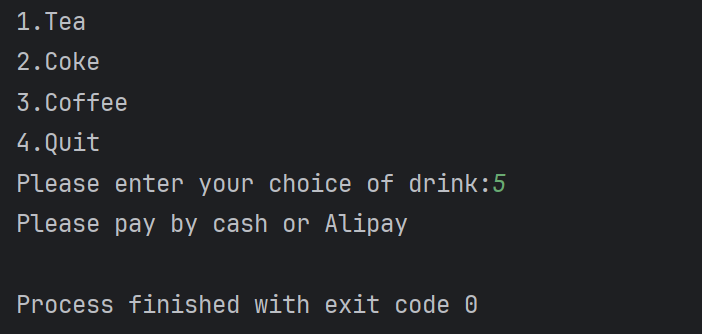
存在问题,以下是简单修复代码
1
2
3
4
5
6
7
8
9
10
11items = ['Tea','Coke','Coffee']
option = 1
for choice in items:
print(str(option)+'.'+choice)
option = option + 1;
print(str(option)+'.Quit')
order = input("Please enter your choice of drink:")
if order and 0 < int(order) < option:
print("Please pay by cash or Alipay")
else:
print("no choice")此判断,输入0或者5,都会说明
no choice看到这里,你或许会想问为什么要用 order and?
原因是,在python中,输入为空即为假,在本题中,如果输入为空,即该
if语句判断为假,直接进入else语句块中。建议自己拿代码去执行一边噢~
Supplementary Exercise
Print function. You can change the ‘sep’ and ‘end’ parameter in the print function. If you type help(print), you will find the default parameter for ‘end’ is \n
- 打印函数。您可以更改打印函数中的“sep”和“end”参数。如果键入help(print),您将发现“end”的默认参数是\n。
Example: change the parameter in the following example and check the result.
例如:更改以下示例中的参数,并检查结果。
1
2print('Hello world','I am from Zhuhai',sep = '-',\
end = '\n');print('in Guangdong')运行结果
1
2Hello world-I am from Zhuhai
in Guangdong解释:
sep即把同一个输出语句中两个字符串的连接换成了sep所设置的值;而end即将该数据语句的结尾增加一个由end设置的值1
2print('Hello world','I am from Zhuhai',sep = '中间',\
end = '结尾\n');print('in Guangdong')运行结果
1
2Hello world中间I am from Zhuhai结尾
in Guangdong
9 * 9 table
1
2
3
4for a in range(1,10):
for b in range(1,a+1):
print(f"{b}*{a}={a*b}",end = ' ')
print('')去执行试一试吧!
SMA-w6_1
Dictionaries
Introduction to Dictionaries
字典
Dictionaries, like lists, are collections of some data. But unlike lists, dictionaries are collections of paired data. For example, you have a collection of student names and their individual student numbers, then dictionaries suit this kind of situation.
- 字典,就像列表一样,是一种数据的集合。但与列表不同的是,字典是一种成对的数据的集合。例如,如果你有一组学生姓名和他们各自的学生号码,那么字典就适合这种情况
1
myCat = {'size': 'fat', 'color': 'gray', 'disposition': 'loud', 'weight': 11}
Braces;
key-valuepairs; you can a key to access its associated value; every key is connected to its value by a colon; individual pairs are separated by commas- 大括号;键-值对;可以通过键来访问其关联的值;每个键都通过冒号与其值相连;各个对之间用逗号分隔
Access the value of a key:
print(myCat[‘size’].title())- 访问键的值
print(myCat[‘size’].title())
- 访问键的值
Square brackets for the key; quotes (single or double)
- 使用方括号表示键;引号(单引号或双引号)
1
print('My cat weighs'+str(myCat['weight'])+ 'kg.')
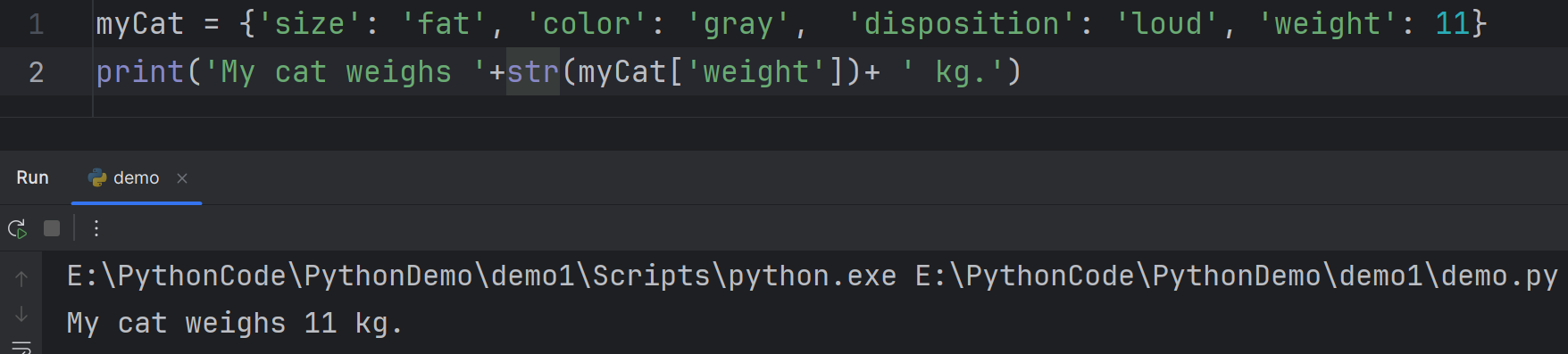
If you would like to use f-string to print it out, make sure you use appropriate quotes so that they match up accordingly
如果想要使用 f-string 打印输出,确保使用适当的引号使其相匹配
1
print(f'My cat is {myCat["disposition"].upper()}')
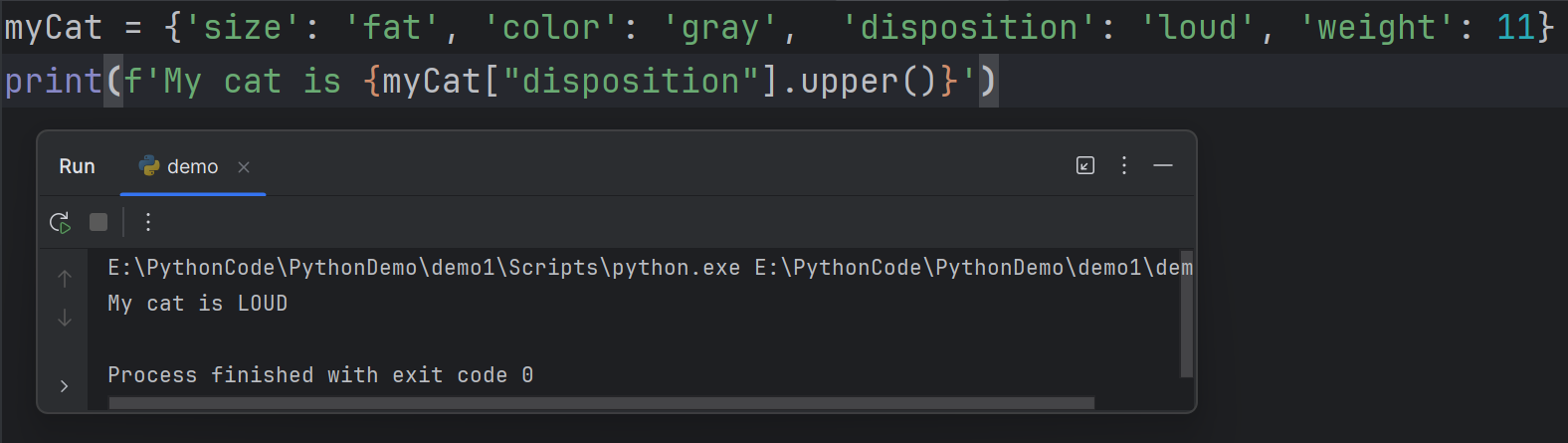
get() method. When you use the key to retrieve the value in a dictionary but the key doesn’t exist, you will get an error.
- 使用 get() 方法。当你使用键来检索字典中的值,但该键不存在时,会产生一个错误。
You can use get() method to set a default value if the requested key doesn’t exist, then you can avoid the error.
你可以使用 get() 方法来设置一个默认值,如果请求的键不存在,那么你就可以避免出现错误。
当你使用字典的
get()方法来获取某个键对应的值时,如果该键不存在于字典中,你可以提供一个默认值作为参数传入get()方法。如果请求的键存在于字典中,那么get()方法会返回该键对应的值;如果请求的键不存在于字典中,get()方法会返回你提供的默认值,而不会抛出错误。这样做可以避免因为请求的键不存在而导致的程序运行时错误1
2
3
4
5classmates = {'paul': '深圳大学', 'Lily': '中山大学'}
# 使用 get() 方法获取键 'peter' 对应的值,如果该键不存在,则返回默认值 '这里没有列出的大学!'
print('Peter is from ' + classmates.get('peter', '这里没有列出的大学!'))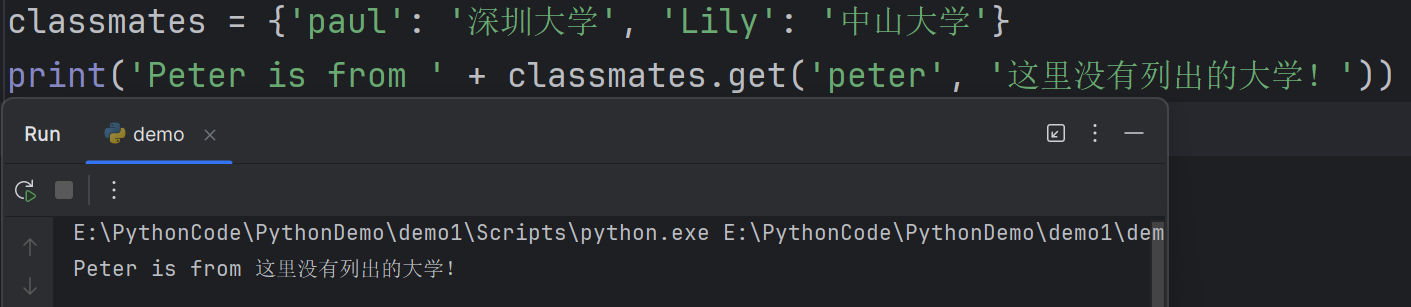
因为键 ‘peter’ 在字典中不存在,返回了默认值。在这个例子中,如果字典
classmates中不存在键'peter',那么使用get()方法并提供了默认值'这里没有列出的大学!',这样就不会出现KeyError错误,而是返回了设定的默认值。
To add new key-value pairs, just create another pair. eg.
myCat['name'] = 'Harry'- 要添加新的键-值对,只需创建另一个键值对。例如:
myCat['name'] = 'Harry'
- 要添加新的键-值对,只需创建另一个键值对。例如:
You can create an empty dictionary and then add key-value pairs to it, eg. students = {}
- 你可以创建一个空字典,然后向其中添加键-值对,例如:
students = {}
- 你可以创建一个空字典,然后向其中添加键-值对,例如:
To modify the values, just give the new value to its associated key. eg.
myCat[‘name’] = 'Hound'- 要修改值,只需给其关联的键赋予新值。例如:
myCat['name'] = 'Hound'
- 要修改值,只需给其关联的键赋予新值。例如:
To remove key-value pairs, use del function.
del myCat['name']- 要删除键-值对,使用 del 函数。例如:
del myCat['name']
- 要删除键-值对,使用 del 函数。例如:
The key in a dictionary has to be unique (works like an index), otherwise only the last pair will be valid, eg.
students = {'Jack': 'Shantou', "Peter": 'Shenzhen', 'Jack': ‘Peking'}字典中的键必须是唯一的(类似于索引),否则只有最后一个键值对将是有效的,例如:
1
2students = {'Jack': '汕头', "Peter": '深圳', 'Jack': '北京'}
print(students['Jack'])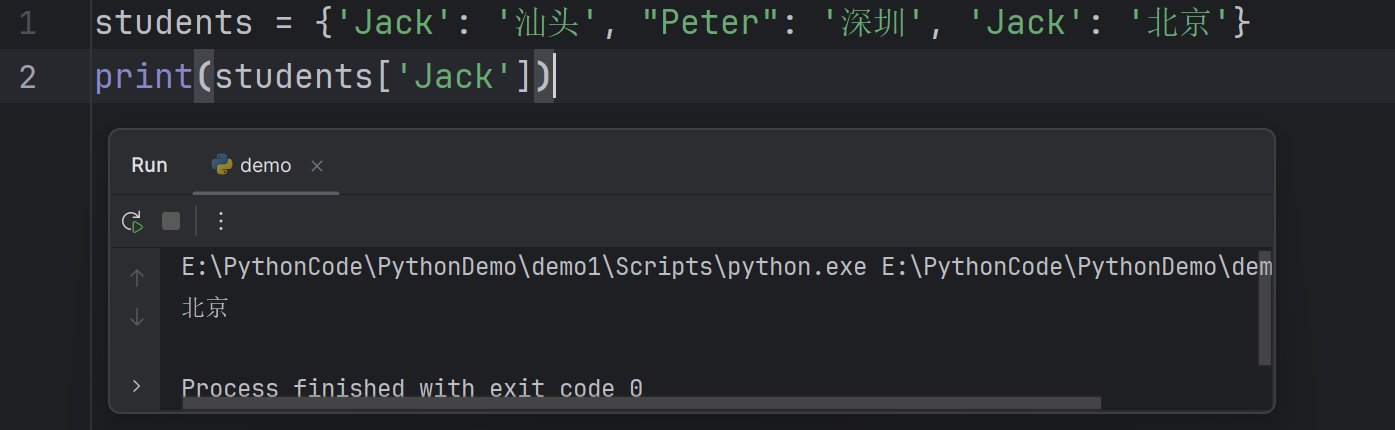
You could use a dictionary to store different kinds of information about one object, or store one kind of information about many objects.
- 你可以使用字典来存储关于一个对象的不同种类的信息,或者存储关于许多对象的一种信息
You could break a large dictionary into several lines. First line contains the opening brace (press Enter after it), each pair then is followed by a comma. It is a good practice to include a comma after the last key-value pa
你可以将一个大字典拆分为多行。第一行包含开放的括号(在其后按 Enter 键),然后每个键值对后跟一个逗号。在最后一个键值对后包含逗号是一个好习惯。
1
2
3
4
5
6studentsEnrolled = {
'Jack': 'Shantou University',
'Peter': 'Shenzhen University',
"Cow": 'Nanchang University',
'Vera': 'UIC'
}
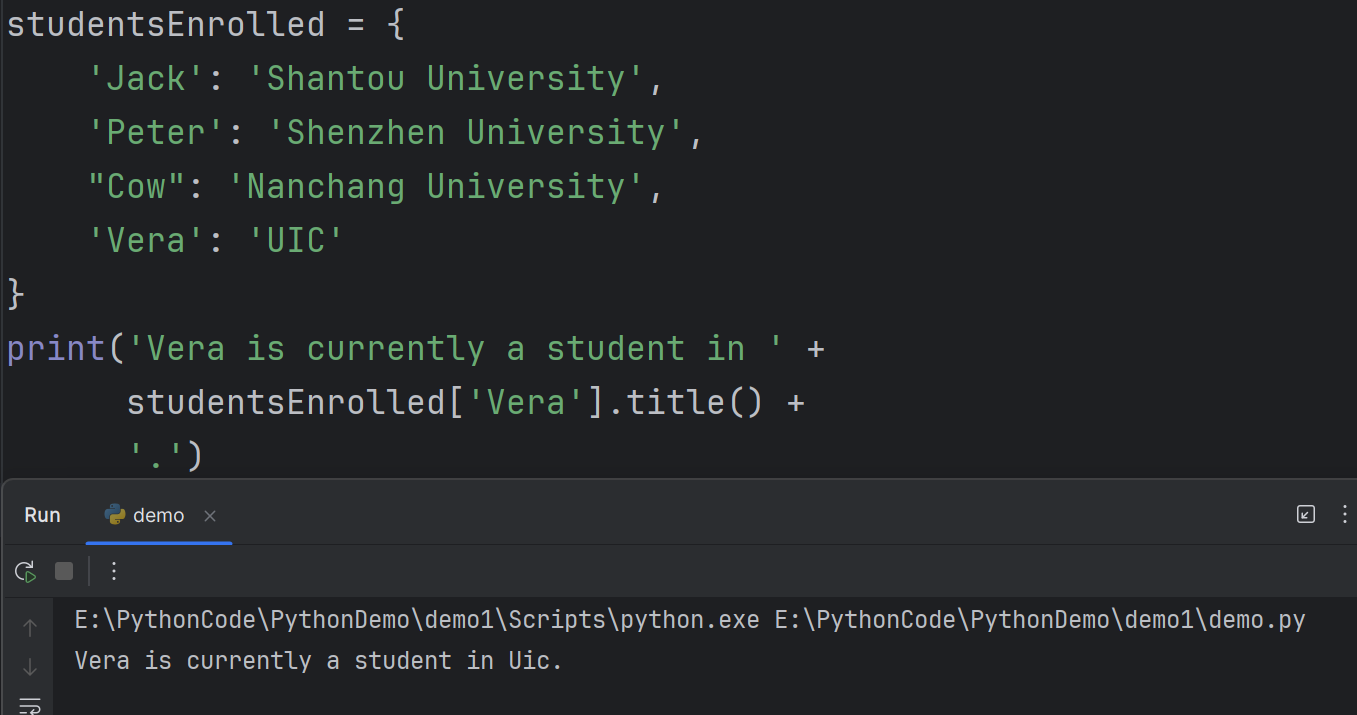
When you print a long string, you could also use + to break the strings to several lines.
当你打印一长串字符串时,你也可以使用加号(+)将字符串拆分为几行。
1
2
3print('Vera is currently a student in ' +
studentsEnrolled['Vera'].title() +
'.')这段代码的意思是,当你打印一条较长的字符串时,你可以在字符串的拼接处使用加号(+)来将字符串拆分为多行,以增加代码的可读性。
Looping through a dictionary
- You can loop through a dictionary by using a For loop, just like looping through a list.
- 你可以使用 for 循环遍历字典,就像遍历列表一样。
- You could choose to loop through all key-value pairs, all the keys, or all the values.
- 你可以选择遍历所有键-值对、所有键,或者所有值。
- To loop through all key-value pairs, use the name of the dictionary followed by the method
items(). For example,- 要遍历所有键-值对,可以使用字典名称后跟方法
items()。例如,
- 要遍历所有键-值对,可以使用字典名称后跟方法
items() method
1 | for k, v in studentsEnrolled.items(): |
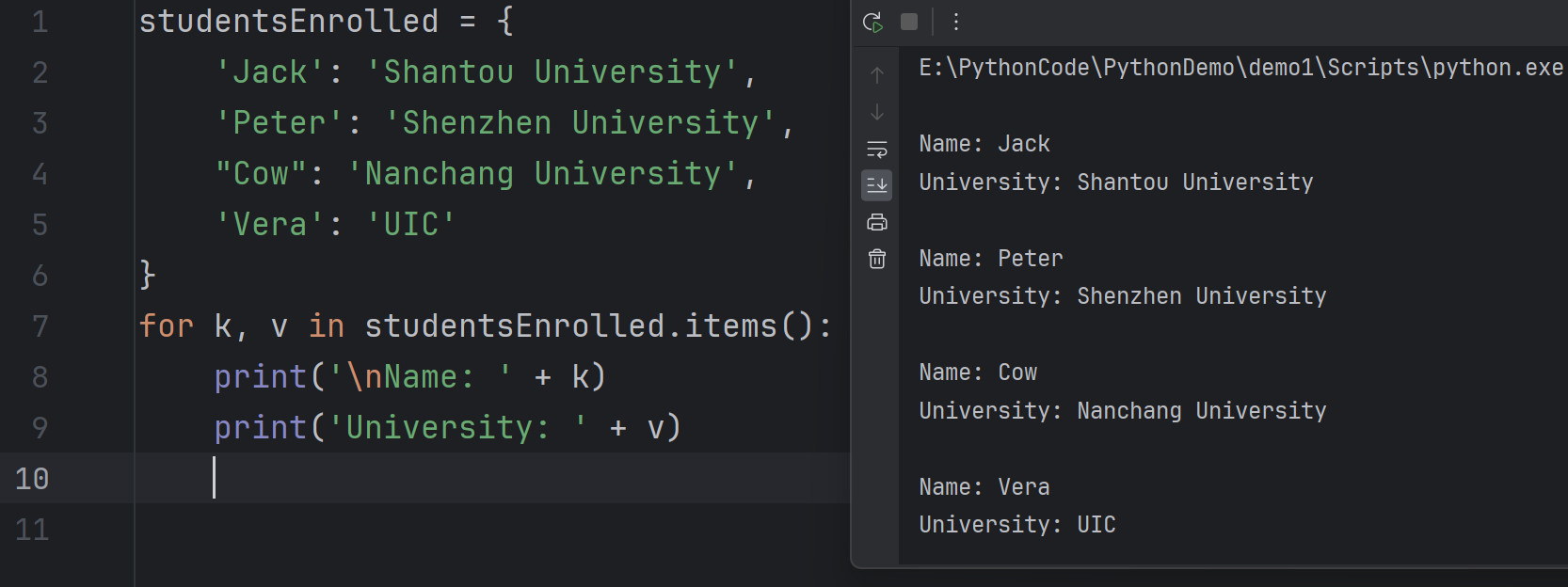
- In this example, k and v are two variables to store the data from the key and the value respectively. It is better to use proper words as the variable names.
- 在这个例子中,
k和v是两个变量,分别用于存储键和值的数据。最好使用恰当的单词作为变量名。
- 在这个例子中,
keys() method
When you only need the data of all the keys, use the keys() method. For example,
当你只需要所有键的数据时,使用 keys() 方法。例如
1
2for name in studentsEnrolled.keys():
print(name.title())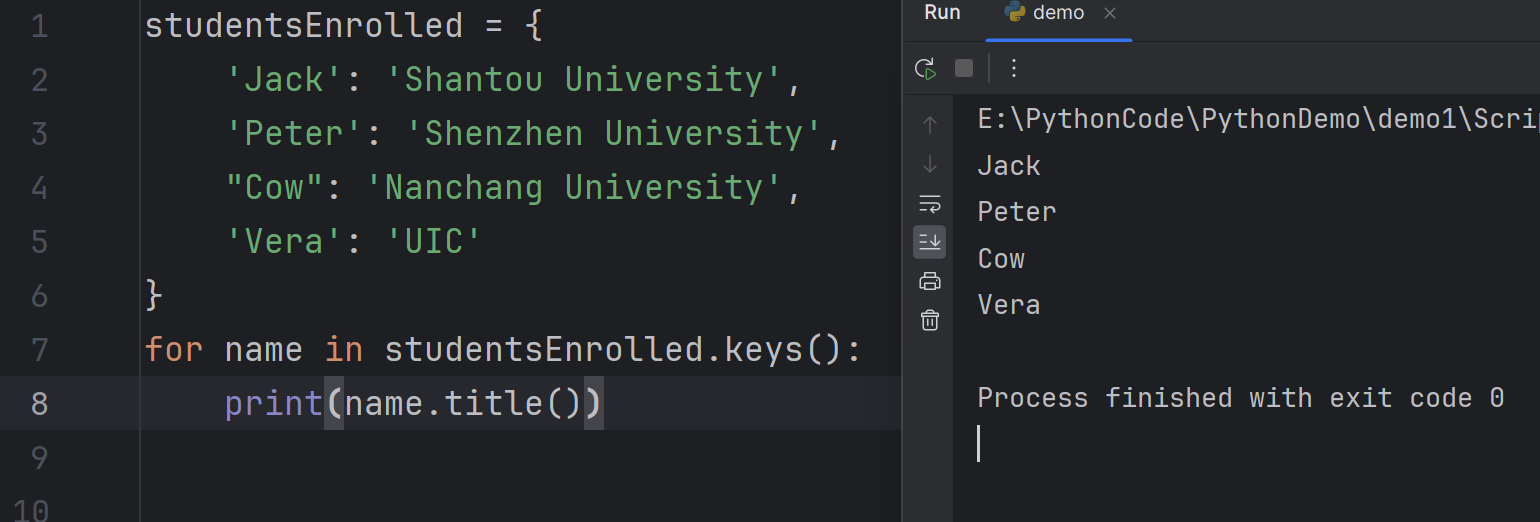
When you don’t use any method in this case, keys() method would be the default method used. keys() method
- 在这种情况下,如果你不使用任何方法,keys() 方法将成为默认使用的方法
You can loop through a dictionary’s keys in a sorted order. For example,
你可以按照排序后的顺序遍历字典的键。例如
1
2for name in sorted(studentsEnrolled.keys()):
print(name.title())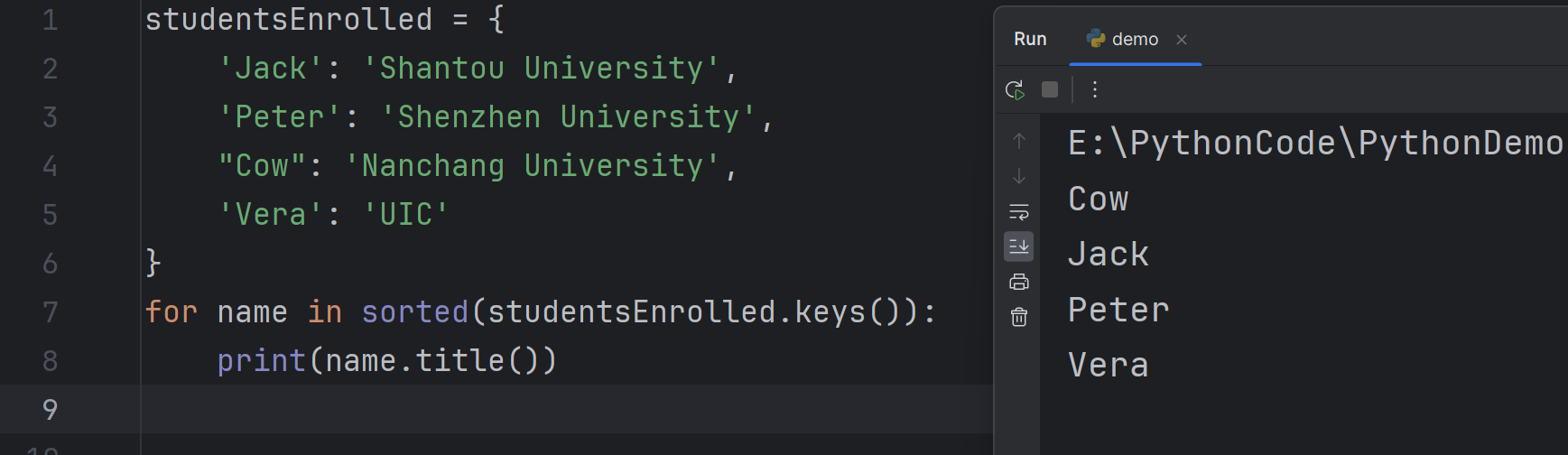
Dictionaries and lists
字典和列表
The items of a list are indexed, so they are arranged in an order and can sliced by using the indices. The items of a dictionary are not indexed, so can’t be sliced. Check the following example about lists:
- 列表的项是有索引的,因此它们是按顺序排列的,可以通过使用索引进行切片。
- 字典的项没有索引,因此不能进行切片。检查以下关于列表的例子:
1
2
3friends = ['jack', 'peter']
classmates = ['peter', 'jack']
friends == classmatesCheck the following example about dictionaries:
- 检查以下关于字典的例子:
1
2
3friends = {'jack': 'UIC', 'paul': '深圳大学', 'Lily': '中山大学'}
classmates = {'paul': '深圳大学', 'Lily': '中山大学', 'jack': 'UIC'}
friends == classmates
values() method
Loop through all values that a dictionary contains, use
values()method- 要遍历字典包含的所有值,请使用
values()方法
1
2for val in studentsEnrolled.values():
print(val)- 要遍历字典包含的所有值,请使用
If you need the values without duplication, you can use set() function.
- 如果你需要不重复的值,你可以使用 set() 函数
1
2for val in set(studentsEnrolled.values()):
print(val)
练习
Define a studentsEnrolled dictionary as we did earlier, add a key-value pair, modify the first key-value pair, so that its value is the same as the value of new pair. Then use For loop to print out all the universities (without duplication)
定义一个类似之前所做的 studentsEnrolled 字典,添加一个键值对,修改第一个键值对,使其值与新对的值相同。然后使用 for 循环打印出所有大学(不重复的)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 定义初始的学生字典
studentsEnrolled = {'Vera': 'UIC', 'Paul': '深圳大学', 'Lily': '中山大学'}
# 添加一个新的键值对
studentsEnrolled['Peter'] = '北京大学'
# 修改第一个键值对的值为新对的值
studentsEnrolled['Vera'] = '北京大学'
print("所有大学(重复的):")
for university in studentsEnrolled.values():
print(university)
# 使用 set() 函数获取所有不重复的大学
unique_universities = set(studentsEnrolled.values())
# 使用 for 循环打印出所有不重复的大学
print("所有大学(不重复的):")
for university in unique_universities:
print(university)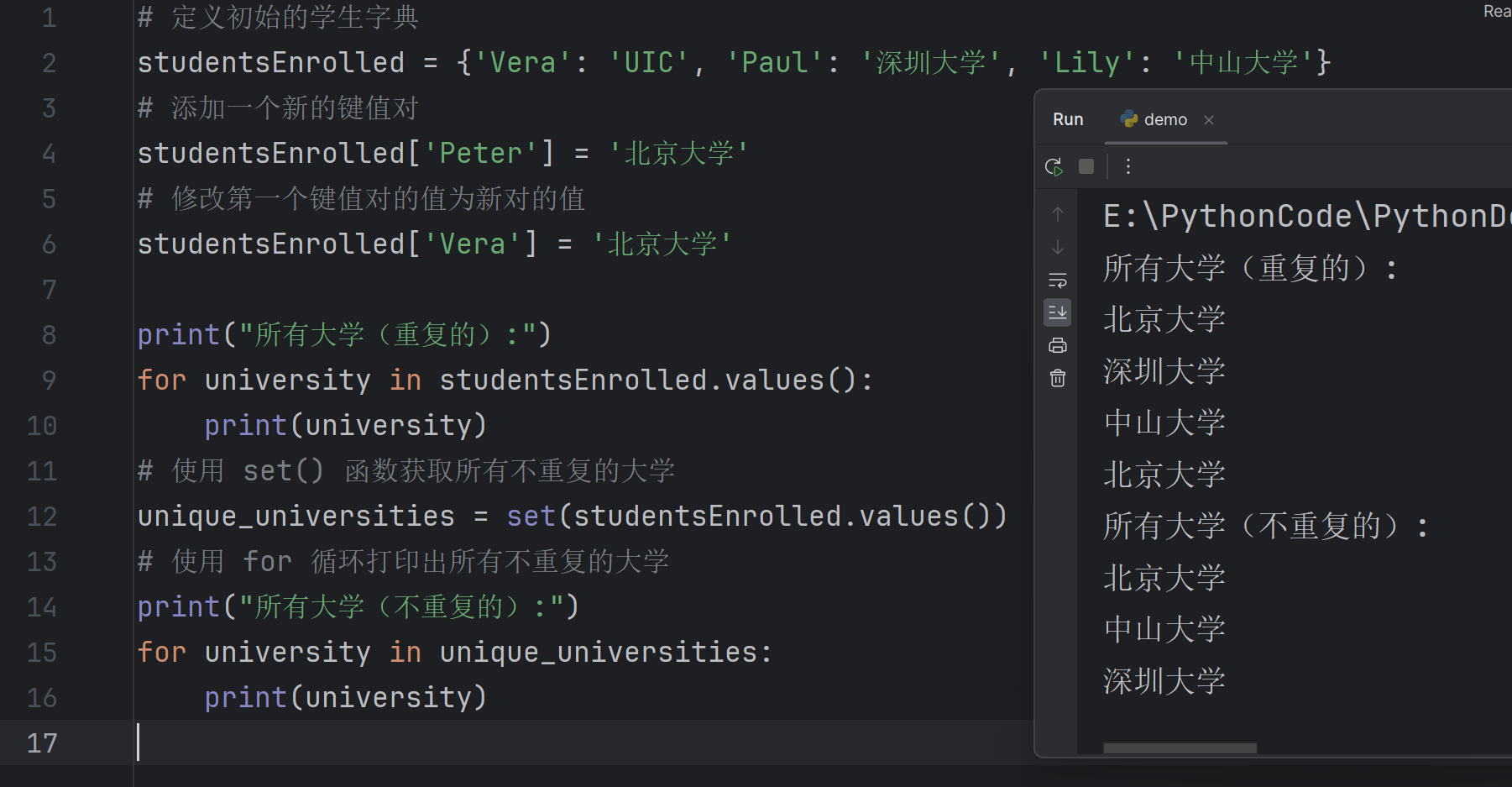
You can use
inornotin to check if a particular value is contained in the keys of a dictionary.- 你可以使用
in或not in来检查字典的键中是否包含特定值
1
2
3
4print('Enter your name: ')
name = input()
if name in studentsEnrolled:
print('Hello ' + name + ', welcome to the conference!')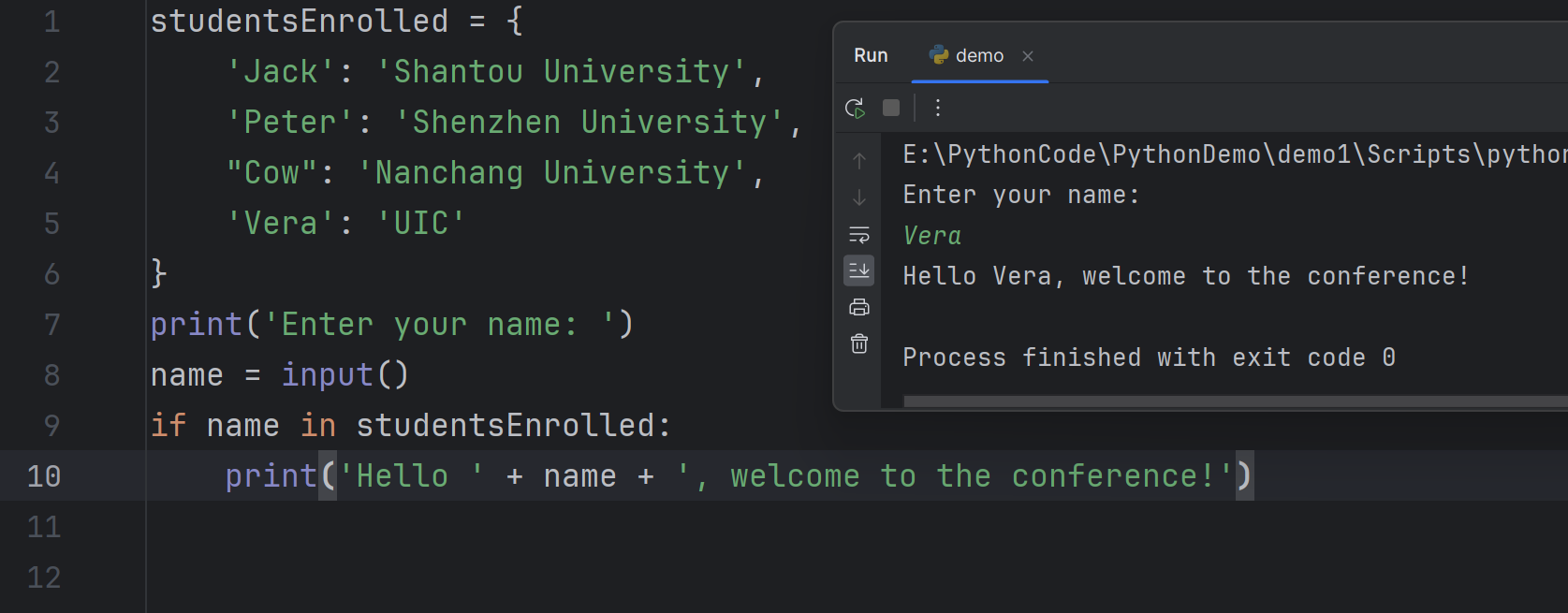
- 你可以使用
The data returned by the keys(), values(), or items() methods are not a list, although you can loop through them. But you can use list() function to change it to a list. sorted() function will also change it to a list.
- keys()、values() 或 items() 方法返回的数据不是列表,尽管你可以遍历它们。但你可以使用 list() 函数将其转换为列表。sorted() 函数也会将其转换为列表。
Nesting
List of dictionaries
- 字典列表
1
2
3student_1 = {'name': 'Jack', 'uni': 'UIC', 'department': 'Journalism', 'year': 4}
student_2 = {'name': 'Peter', 'uni': 'Shenzhen', 'department': 'Engineering', 'year': 3}
students = [student_1, student_2]To locate a particular value, you can use
student[1]['name']- 要定位特定的值,你可以使用
student[1]['name']
- 要定位特定的值,你可以使用
A list in a dictionary. For example,
字典中的列表。例如,
1
students = {'name': 'Jack', 'department': 'Journalism', 'courses': ['Research Methods', 'Introduction to Python', 'Digital Media']}
Exercise: write a program to print out the above information in the following format:
练习:编写一个程序以以下格式打印出上述信息:
1
2
3Jack from the Department of Journalism has finished the following courses:
Research Method
Introduction to Python1
2
3
4
5
6
7students = {'name': 'Jack', 'department': 'Journalism',
'courses': ['Research Methods', 'Introduction to Python', 'Digital Media']}
print(students['name'] + ' from the Department of ' + students['department'] + ' has finished the following courses:')
for course in students['courses']:
print(course)
A dictionary in a dictionary
- 字典中的字典
For example, you have a dictionary of user information with the username being the unique key, but the value of a particular username could be another dictionary containing detailed information about that username
例如,你有一个包含用户名作为唯一键的用户信息字典,但特定用户名的值可能是另一个包含有关该用户名的详细信息的字典。
1
2
3
4
5
6
7
8
9
10
11
12
13
14users = {
'poppy':{
'name':'Vera',
'city':'Shangrao',
},
'tiger':{
'name':'Lily',
'city':'Zhuhai',
},
}
for username,userinfo in users.items():
print('Username:' + username)
print('\tNickname is ' + userinfo['name'].title())
print('\tLocation is in ' + userinfo['city'].title())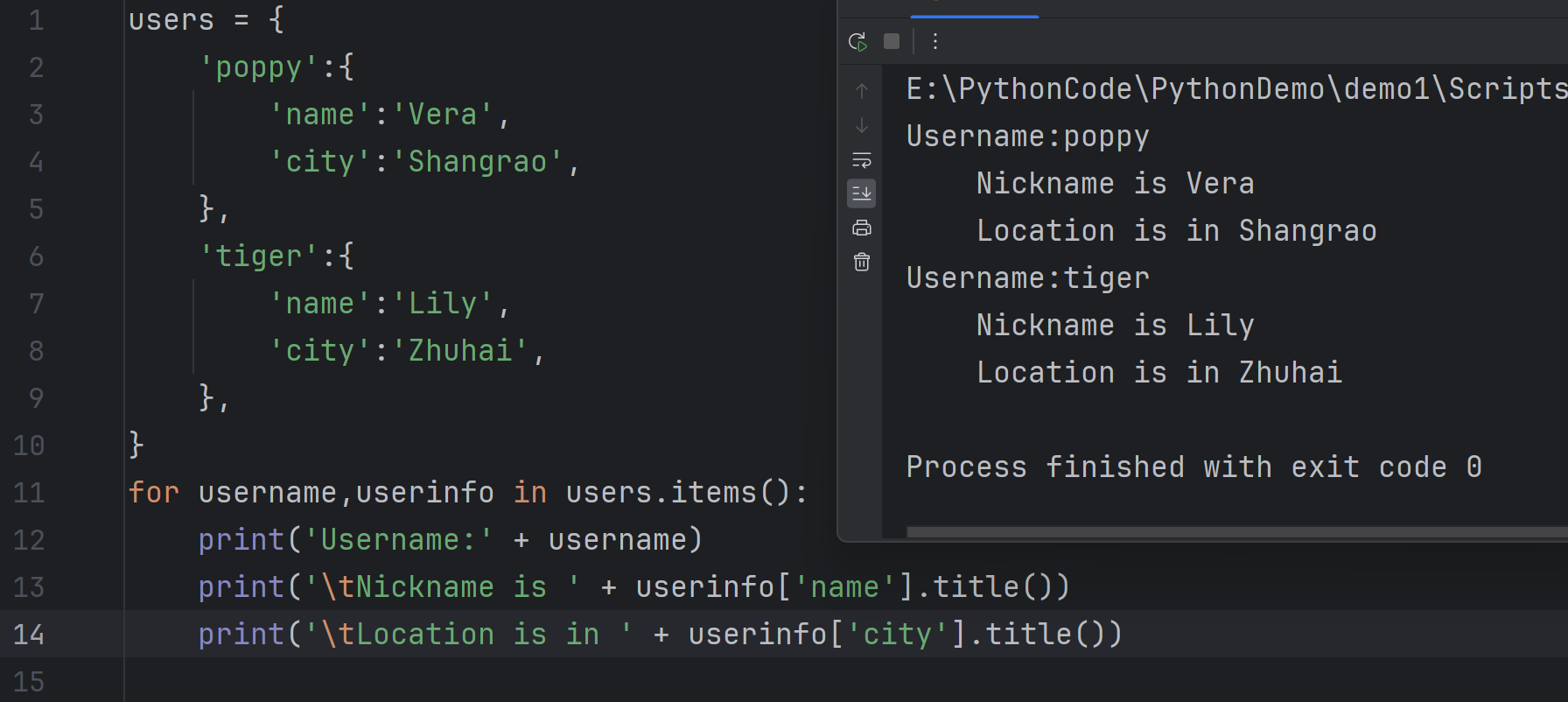
SMA-w7_1
While Loop
- while 循环
Introduction to while loops
If you want to loop through a certain amount of items in a collection or carry out a task for a certain amount of times (eg. when using range function), the for loop works well
- 如果你想循环遍历集合中的一定数量的项,或者执行某个任务一定次数(例如使用 range 函数时),for 循环很适合
The while loop runs as long as a certain condition is true
- while 循环则会在某个条件为真时一直运行
1 | current_num = 1 |
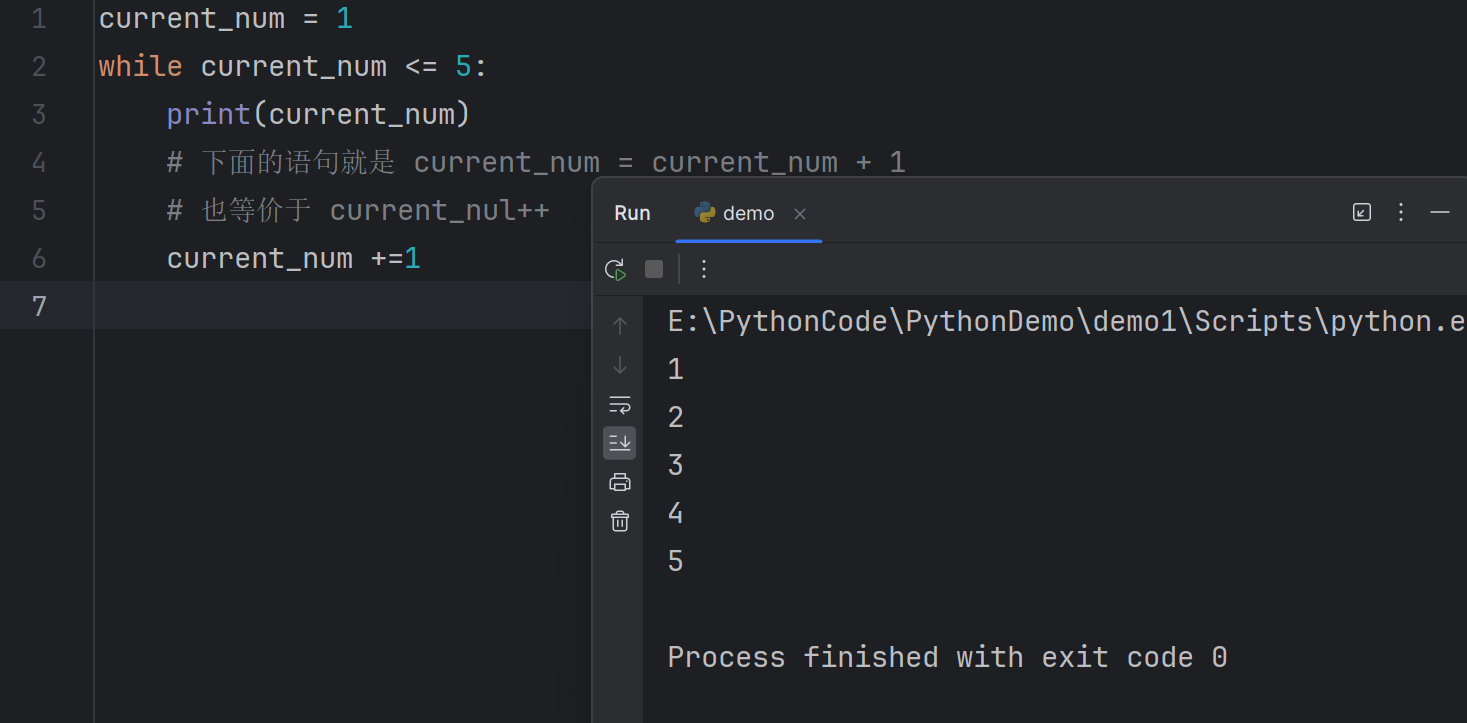
The while loop suits many real life cases. For example, a shop process orders from customers (you won’t know how many customers would place orders)
- while 循环适用于许多现实生活场景。例如,商店处理顾客的订单(你不知道会有多少顾客下订单)。
The most important thing in controlling the while loop is to set a suitable conditional test so that the programme can stop running.
- 控制 while 循环最重要的是设置适当的条件测试,以便程序能够停止运行。
There are different ways of terminating the while loop
- 终止 while 循环有不同的方法。
User intervention
- 用户干预
Define a quit value and keep the programme running until the quit value is entered
定义一个退出值,并保持程序运行,直到输入了退出值。
1
2
3
4
5
6prompt = "Please enter your name, "
prompt += "\nenter 'quit' to end the program:"
message = ''
while message != 'quit':
message = input(prompt)
print(f"Hello {message},have a good day!\n")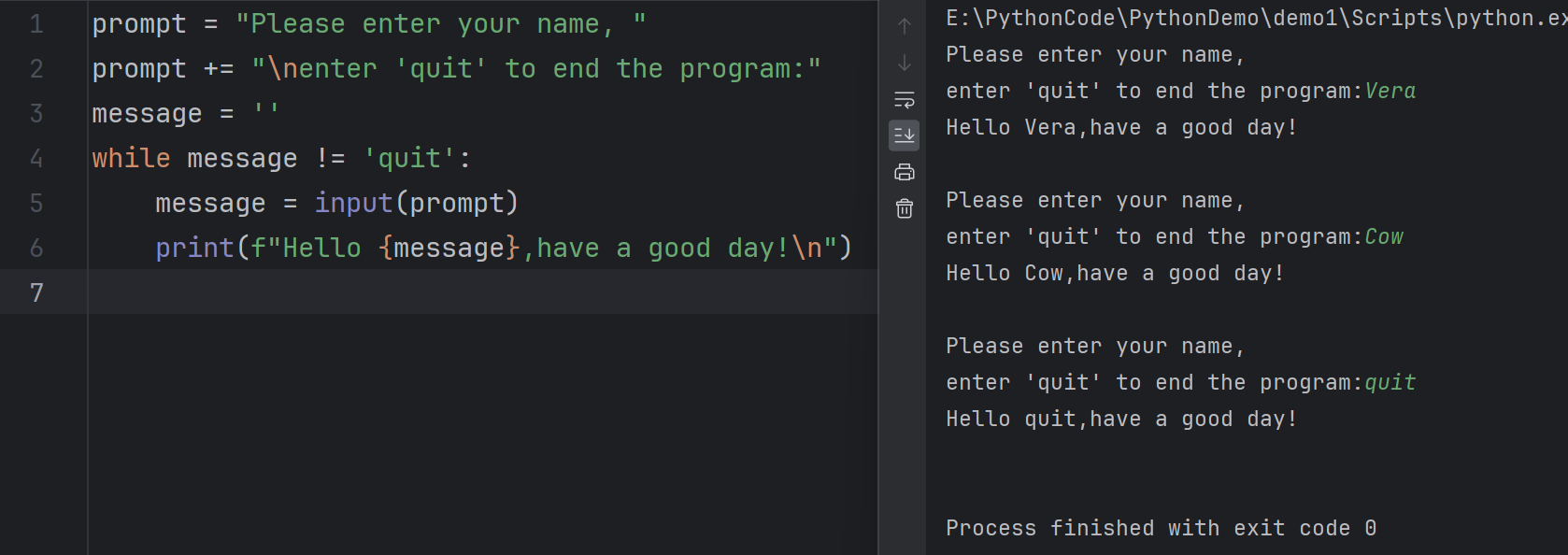
我们可以看到,上面的代码其实是存在问题的,即使你输入了quit,依然会打印出后面的语句,这是我们不期望的,我们想要的是输入了quit直接退出,不要打印语句。那么该如何修改呢?
我们可以在while里面再加入一个判断,当输入的值不为quit的时候,才会打印语句,而如果是quit,则不会打印语句
1
2
3
4
5
6
7prompt = "Please enter your name, "
prompt += "\nenter 'quit' to end the program:"
message = ''
while message != 'quit':
message = input(prompt)
if message != 'quit':
print(f"Hello {message},have a good day!\n")
Using a flag
If many possible events might stop the programme, testing all the conditions in one while statement might be complicated
- 如果有许多可能的事件可能会停止程序,那么在一个
while语句中测试所有条件可能会很复杂。
You can define one variable to control the loop, and then change the value of this variable (a flag) when certain conditions are met.
- 你可以定义一个变量来控制循环,然后当满足特定条件时改变这个变量的值(一个标志)
In the previous example, you may want to add a condition to terminate the loop when a name is not in your friends list
在前面的例子中,当一个名字不在你的朋友列表中时,你可能希望添加一个条件来终止循环
1
2
3
4
5
6
7
8
9
10
11
12
13
14prompt = "Please enter your name, "
prompt += "\nenter 'quit' to end the program:"
friends = ['Vera','Maple','Love']
active = True
message = ''
while active:
message = input(prompt)
if message.lower() == 'quit':
active = False
elif message.title() not in friends:
active = False
print("Sorry,you are not invited to this party!")
else:
print("Hello"+message.title()+",enjoy!")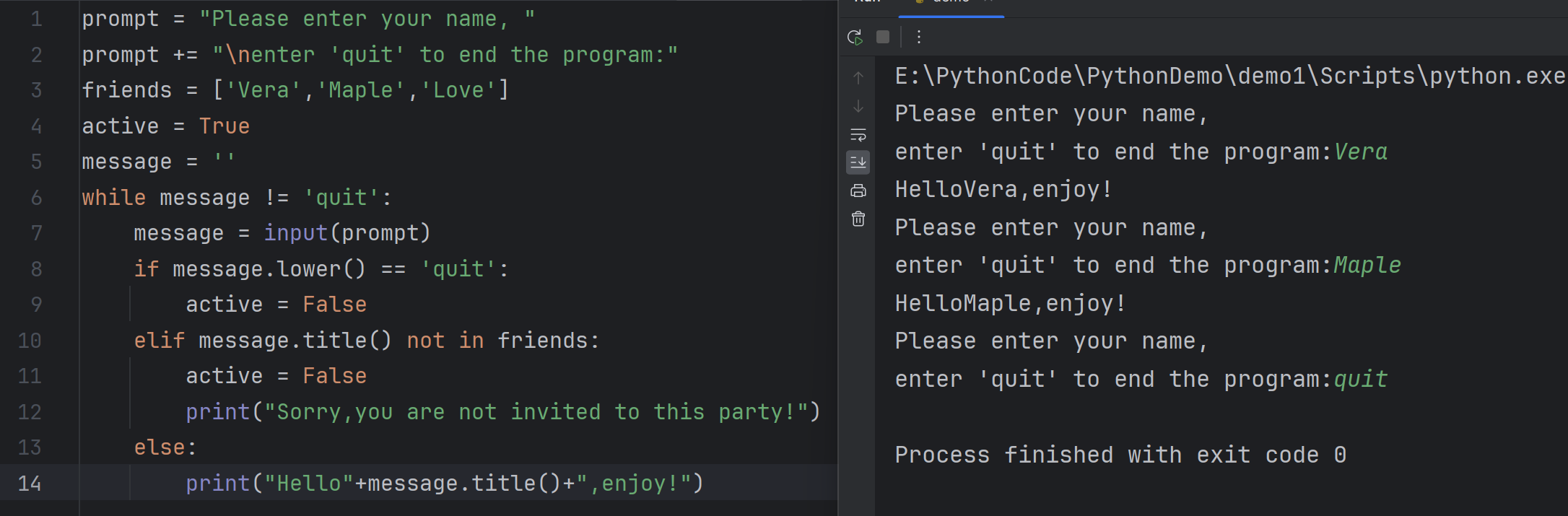
Using break
You can use the break statement to exit the loop without running any remaining code
你可以使用 break 语句退出循环,而不运行任何剩余的代码
1
2
3
4
5
6
7
8
9prompt = "Please enter your name, "
prompt += "\nenter 'quit' to end the program:"
while True:
message = input(prompt)
if message == "quit":
break
else:
print(message+",have a nice day!")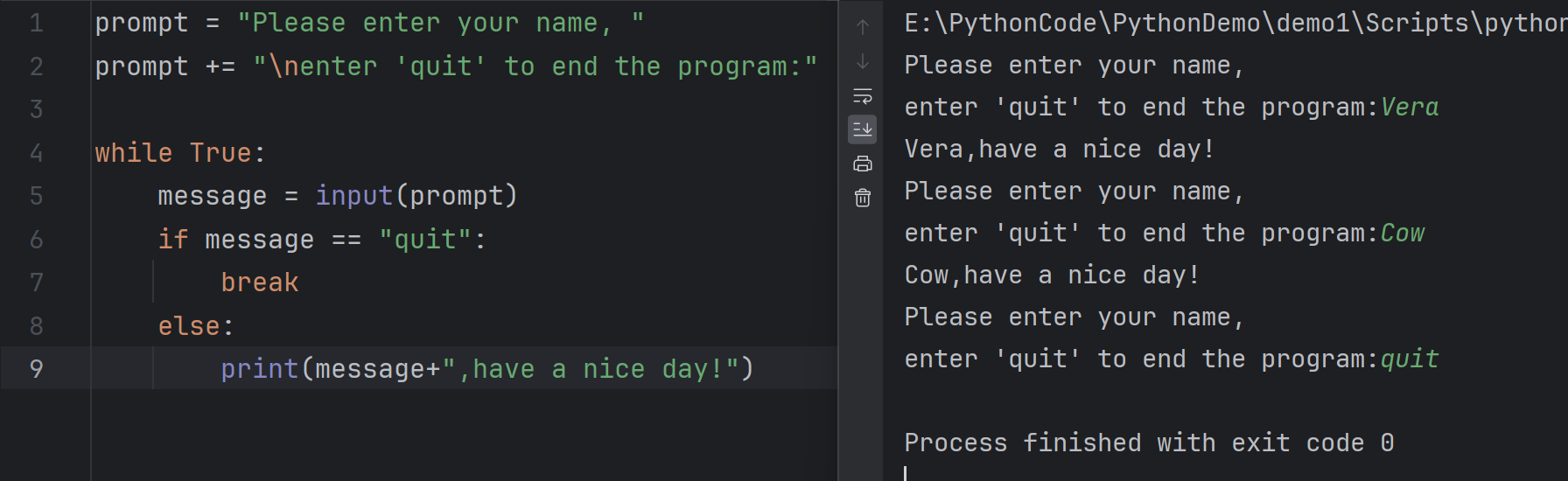
A loop with While True statement will run forever unless it reaches a break statement.
- 一个带有 While True 语句的循环会一直运行,除非它遇到一个 break 语句。
The function of the programme is similar to the previous ones
- 程序的功能与之前的类似
Using continue in a loop
在循环中使用continue
You can use the continue statement to ignore the rest of the loop and return to the beginning. For example
可以使用 continue 语句来忽略循环的其余部分并返回到开头。例如
1
2
3
4
5
6a = 0
while a < 10:
a += 1
if a % 2 ==0:
continue
print(a)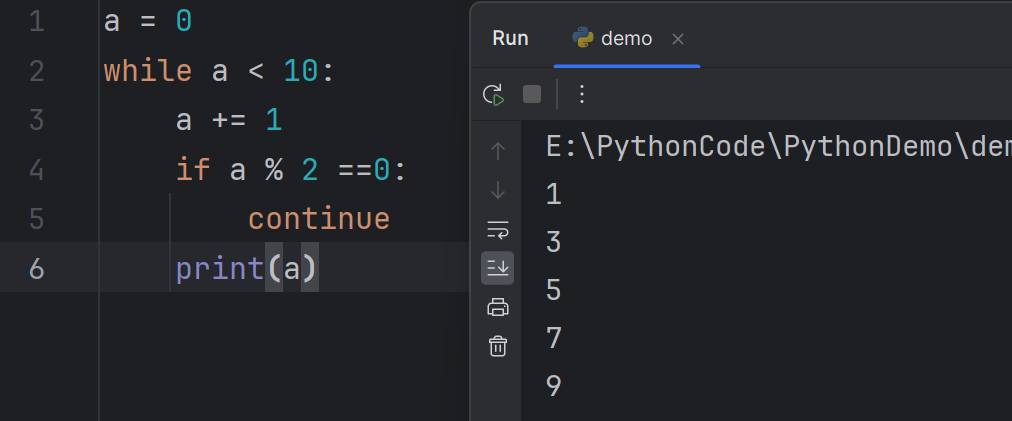
It performs the same function as the following programme
它执行与以下程序相同的功能
1
2
3
4
5a = 0
while a < 10:
a += 1
if a % 2 !=0:
print(a)
Avoiding infinite loops
- 避免无限循环
For while loops, it is important to avoid infinite loops. You need to set a condition so that the loop could terminate. For example:
对于 while 循环,避免无限循环是很重要的。你需要设置一个条件,使得循环可以终止。例如
1
2
3x = 1
while x<=5:
print(x)
Using while loops for lists
For loops are effective for looping through a list, but you shouldn’t modify a list inside a for loop. If you do, the index value of the items of a list might change and Python will have trouble keeping track of the items in a list
for 循环适用于遍历列表,但是你不应该在 for 循环内修改列表。如果这样做,列表中项的索引值可能会改变,Python 将难以跟踪列表中的项
这是因为在遍历列表的过程中,Python 会根据索引逐个访问列表中的项。如果在循环中修改了列表,可能会改变列表的长度或顺序,从而导致索引值和列表内容不匹配,可能引发意料之外的错误。
1
2
3
4list = ['peter','john','lily']
for i in list:
print(i)
list.remove(i)
Moving items between lists
移动列表项之间的一种方法是使用列表的 pop() 和 append() 方法。这允许你从一个列表中取出项并将其添加到另一个列表中
1 | source_list = [1, 2, 3, 4, 5] |
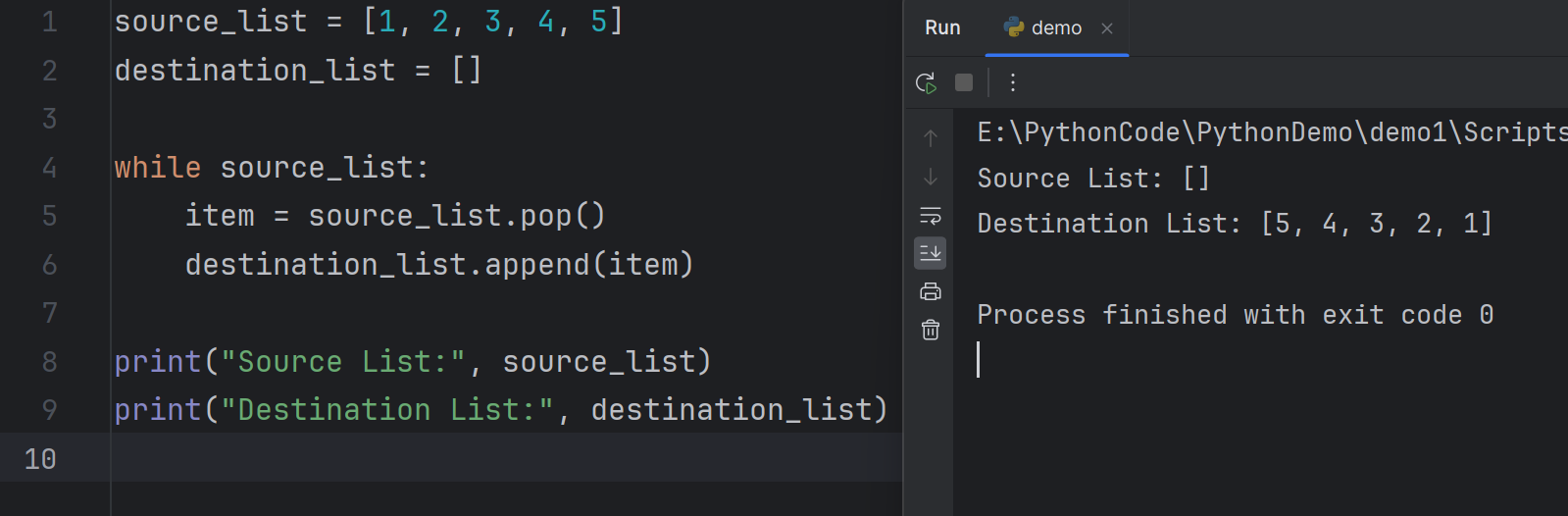
为什么是 5,4,3,2,1?
Removing specific values from a list
Use while to remove all instances of a particular value
使用 while 循环来删除列表中所有特定值的实例。
1
2
3
4pets = ['dog','cat','pig','lion']
while 'lion' in pets:
pets.remove('lion')
print(pets)这个程序首先定义了一个名为
pets的列表,其中包含了一些宠物的名称。然后,它进入了一个while循环,该循环的条件是'lion'在pets列表中。在循环内部,程序使用remove()方法来删除列表中的'lion'。这个过程会一直重复,直到'lion'不再在列表中为止。最后,程序打印出删除'lion'后的pets列表
Exercise
Exercise 1: Define a list with some items, use insert() and append() methods to add a couple of strings containing one empty space as new items to the list. Then write a programme to delete all the empty strings
练习1:定义一个包含一些项的列表,使用
insert()和append()方法将几个包含一个空格的字符串作为新项添加到列表中。然后编写一个程序来删除所有的空字符串。One possible solution by using a for loop there might be an index problem though
一个可能的解决方案是使用 for 循环,尽管可能会有索引问题
1
2
3
4
5list = ['hello',' ','I','can','see',' ','you']
for i in list:
if i == ' ':
list.remove(' ')
print(list)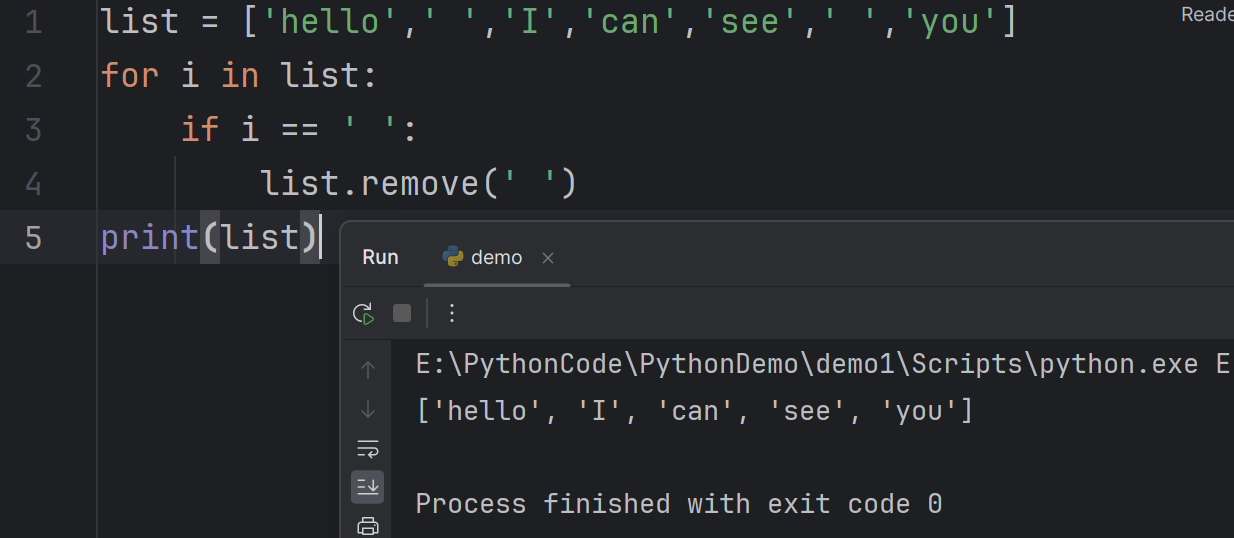
What if one of the items contains two or more empty spaces?
如果其中一个项包含两个或更多个空格呢?
1
2
3
4
5
6list = ['hello',' ','I','can','see',' ','you']
for i in list:
# 使用strip去除空格,如果只包含空格,那么去除空格后的长度即为0
if len(i.strip()) == 0:
list.remove(i)
print(list)But what would happen if
list = ['hello', ' ' , ' ', 'there', 'I', 'am', 'from', 'China', ' '](the index problem will happen here如果列表为
['hello', ' ', ' ', 'there', 'I', 'am', 'from', 'China', ' '](这里将会出现索引问题)。1
2
3
4
5
6# 该代码会出现问题
list = ['hello', ' ' , ' ', 'there', 'I', 'am', 'from', 'China', ' ']
for i in list:
if len(i.strip()) == 0:
list.remove(i)
print(list)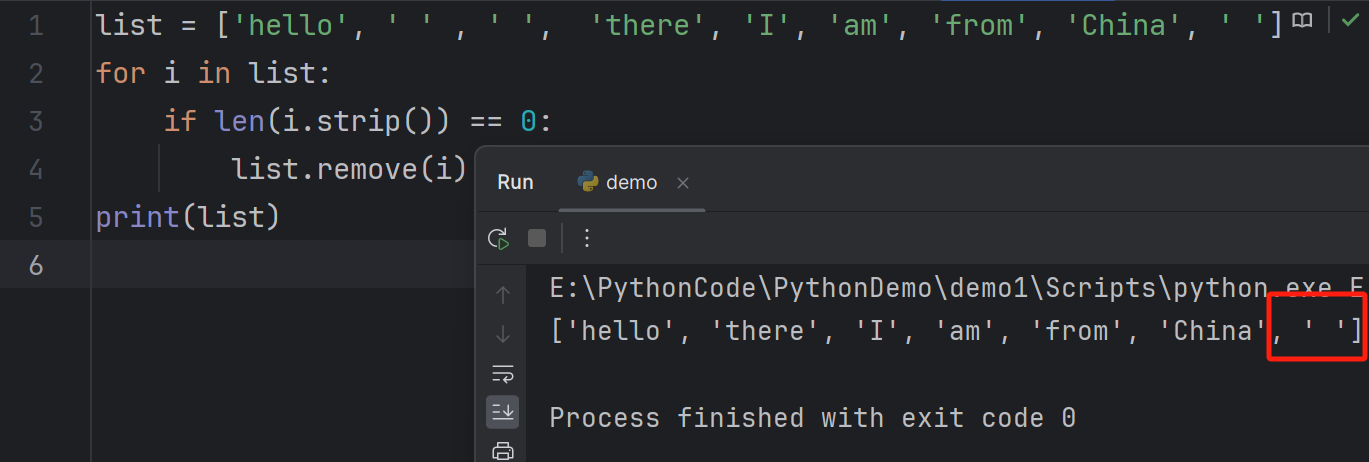
可以发现最后一个空格没有被删除,为什么呢?
当删除空格时,列表的长度会缩短,导致循环未能正确处理最后一个空格。具体来说,在第一次迭代时,
list中的第一个空格被删除了(此时的索引为 1),此时列表变为['hello', ' ', 'there', 'I', 'am', 'from', 'China', ' '],但循环的索引已经过了第二个空格(索引 1 已被访问过,但是现在由于删除了之前索引为 1 的空格,索引 1 又变成了空格(原来的索引 2 的空格))。然后,第二次迭代发现第二个空格,但第三个空格在之后的索引位置,因此没有被删除。一个解决的办法,就是用
while循环1
2
3
4list = ['hello', ' ' , ' ', 'there', 'I', 'am', 'from', 'China', ' ']
while ' ' in list:
list.remove(' ')
print(list)为什么使用while就可以呢?
使用
while循环可以避免索引问题,因为它不会随着列表的改变而改变迭代的索引。在while循环中,我们可以根据需要控制迭代的过程,直到达到某个特定的条件为止。具体地说,在这种情况下,使用
while循环允许我们在遍历列表的同时,动态地删除满足条件的项,而不会影响到迭代过程中的索引。这样就可以确保所有的空字符串都被正确地删除,而不会受到删除操作对索引的影响。However, it is a clumsy solution because there can be more empty spaces in an item. Can you think of a better solution
然而,这是一个笨拙的解决方案,因为一个项中可能会有更多的空格。你能想到更好的解决方案吗?
1
2
3list = ['hello', ' ' , ' ', 'there', 'I', 'am', 'from', 'China', ' ']
list = [i for i in list if len(i.strip())!=0]
print(list)这行代码使用了列表推导式来创建一个新的列表。具体来说,它遍历了原始列表
list中的每一个元素i,并且只保留那些满足条件len(i.strip()) != 0的元素。条件
len(i.strip()) != 0的含义是,对于列表中的每个元素i,先使用strip()方法去除字符串两端的空格,然后计算其长度。如果长度不等于 0(即字符串不为空),则该元素满足条件,会被保留在新的列表中。因此,这行代码的作用是创建一个新的列表,其中只包含原始列表中不为空的字符串元素。
SMA-w8_1
Functions
Introduction to functions
Functions are named blocks of code that are designed to perform a specific task.
- 函数是设计用来执行特定任务的命名代码块。
Using functions make it significantly simpler to perform a task repeatedly. When you call a function, Python will run the code inside the function.
- 使用函数使重复执行任务变得更加简单。当你调用一个函数时,Python会运行函数内部的代码。
Using functions make your programme easier to write, read, test, and fix
- 使用函数使你的程序更容易编写、阅读、测试和修复。
There are many built-in functions in Python, such as print(), abs(), max(), min(), list(), sorted(), type()
- Python中有许多内置函数,如
print()、abs()、max()、min()、list()、sorted()、type()。
There are other data type transformation functions such as int(), str(), float()
还有其他数据类型转换函数,如
int()、str()、float()。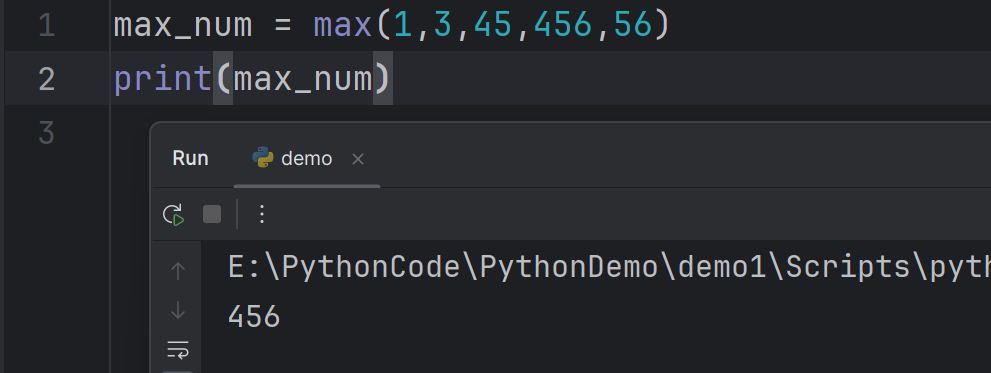
Defining a function
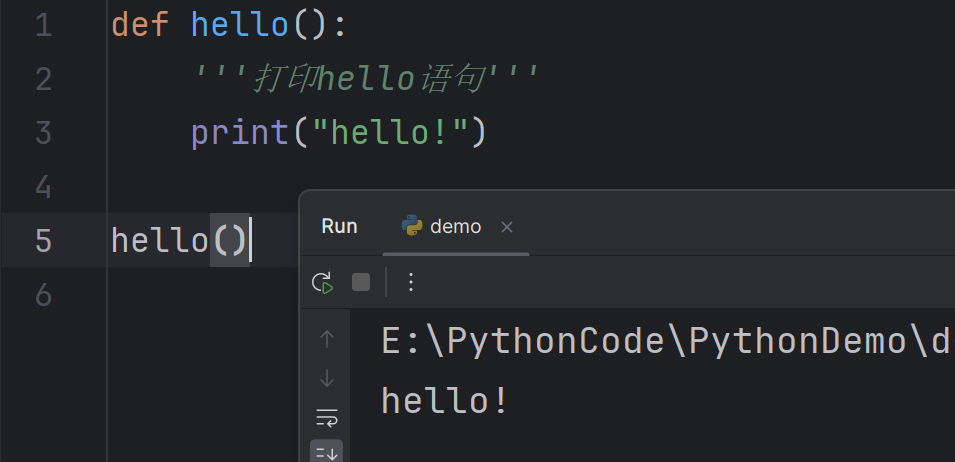
这里我们使用def关键字去定义了一个函数,名叫hello,括号里面是这个函数里面会用到的数据,也叫参数,我们给函数一些参数,供函数使用,现在这个函数的括号里面是空的,意味着它不需要参数就可以正常的执行,函数其实是为了更好的重复利用代码,比如现在这个函数,你想打印hello的时候,就不再需要print("hello")了,而只需要调用我们现在的这个函数hello(),实际上调用函数就是执行函数里面的语句,你也可以理解为它是一堆代码的别称。现在这个只是一个简单的函数,当需要复杂的操作,代码量多起来之后,你就可以体会到函数的便捷了。
调用函数,也叫 function call。一个函数里面的内容,叫函数体( body of the function ) 。现在这个函数是没有参数的,我们来给他一些参数,看看他会发生什么?
Passing information to a function
In the previous example, if you want to greet people with their names, you can add a variable into the parentheses of the function.Then you can pass a name to the function when it is called
在前面的示例中,如果你想用人们的名字来问候,你可以将一个变量添加到函数的括号中。然后,当调用函数时,你可以传递一个名字给它。
1
2
3
4
5def hello(name):
'''打印hello语句'''
print(f"hello!,{name}")
hello('Vera')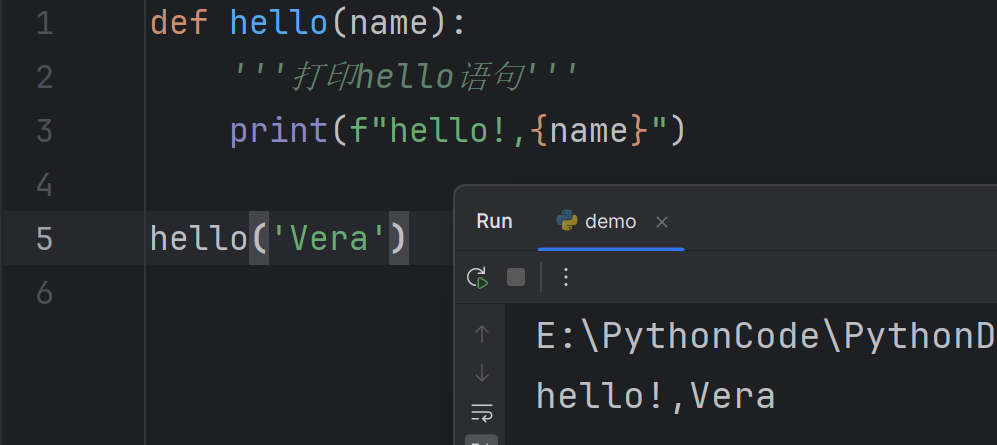
The variable of name is a parameter, Lucyis an argument (can be used interchangeably)
变量
name是一个形参,而“Lucy”是一个入参(可以互换使用)。“入参”和”形参”是关于函数参数的两个不同概念:
- 形参(Formal Parameter):
- 形参是函数定义时在括号内声明的参数,用于指定函数接受的输入。
- 形参是函数内部的变量名,用于在函数体内引用传递给函数的值。
- 形参在函数定义时起作用,但在函数被调用时并不具有实际值。
- 入参(Actual Parameter):
- 入参是函数在调用时传递给形参的实际值。
- 入参是函数调用时提供的实际数据或变量,用于填充函数定义中的形参。
- 入参在函数被调用时起作用,用于给函数传递信息和执行操作。
简而言之,形参是函数定义时声明的变量,而入参是在函数调用时提供给形参的实际值。形参用于在函数内部引用传递给函数的值,而入参用于向函数传递具体的数据或变量。
- 形参(Formal Parameter):
Passing arguments
A function can have multiple parameters, and you may need to pass multiple arguments to the function.
- 一个函数可以有多个参数,你可能需要向函数传递多个入参。
You have several ways to match up the parameters and the arguments, the simplest way to do this based on the order of arguments (positional arguments)
- 有几种方法可以匹配参数和参数,最简单的方法是根据参数的顺序(位置参数)。
Example, define a function to print out student information (with parameters to receive the information of name, age, city)
例如,定义一个函数来打印学生信息(使用参数来接收姓名、年龄和城市信息)
1
2
3
4
5
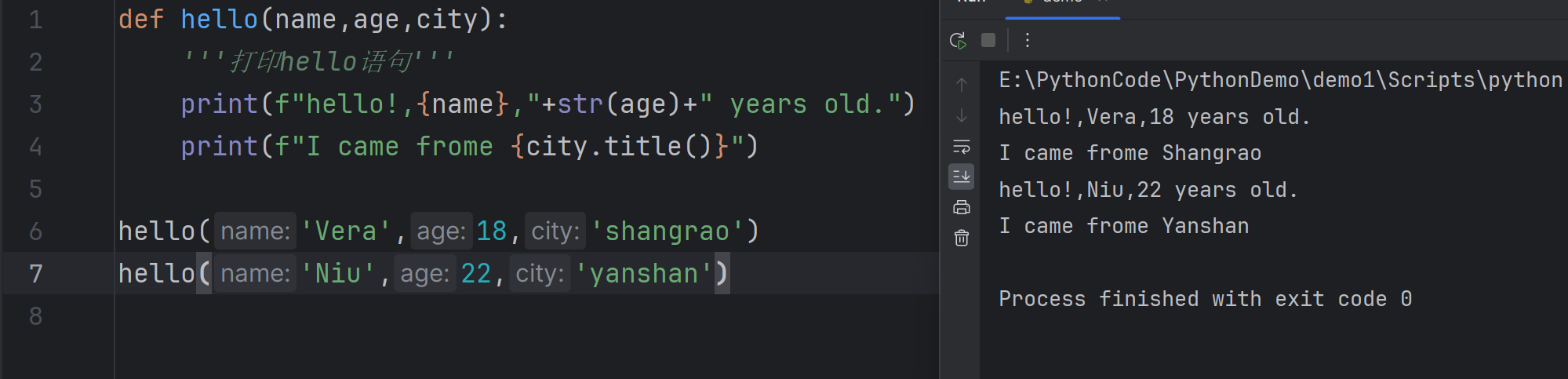
6def hello(name,age,city):
'''打印hello语句'''
print(f"hello!,{name},"+str(age)+" years old.")
print(f"I came frome {city.title()}")
hello('Vera',18,'shangrao')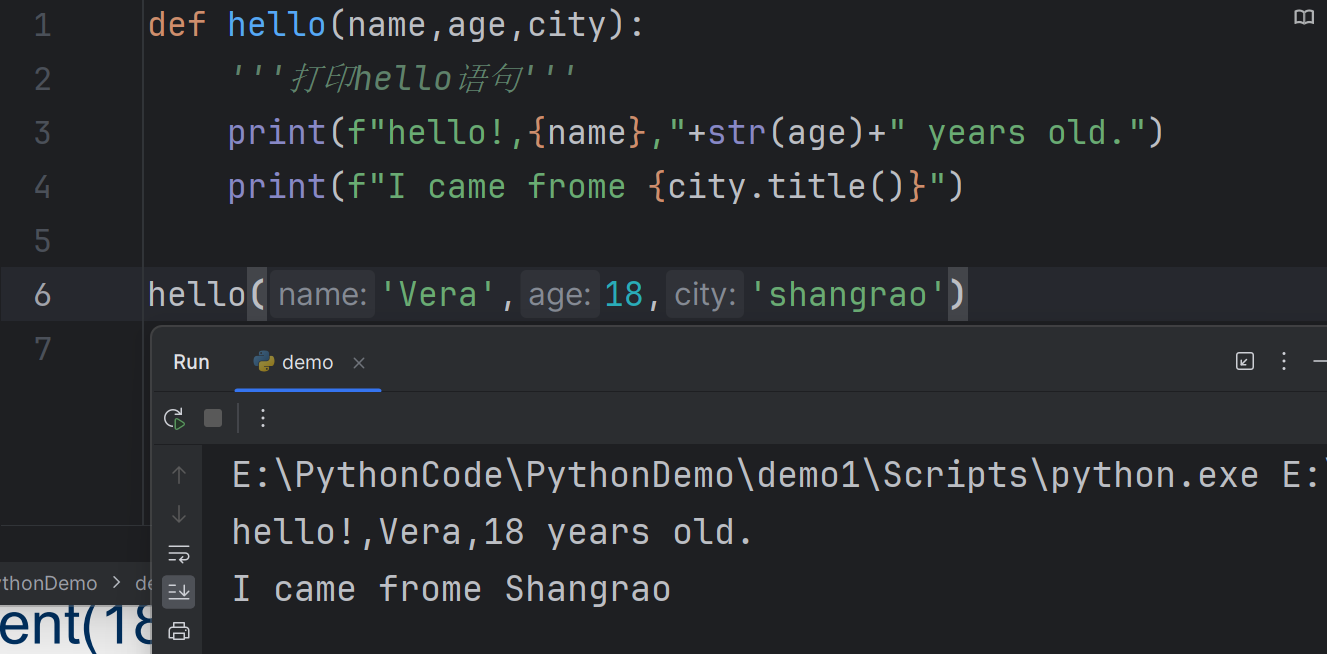
Multiple function calls
You can call a function as many times as needed
你可以根据需要调用一个函数多次。
Keyword Arguments
关键字参数
A keyword argument is a name-value pair. When you pass the keyword arguments to the function, there won’t be confusions.
- 关键字参数是一对 名称-值 。当你将关键字参数传递给函数时,不会产生混淆。
student(name=‘sabrina’,age=18,city=’beijing’)
student(age=18,city=’beijing’,name=‘sabrina’)
You will get the same outputs from the above two ways of passing arguments.
- 你将从上述两种传递参数的方式中得到相同的输出。
You need to provide the exact amount of arguments to the function (you will receive error message if you don’t)
- 你需要向函数提供精确数量的参数(如果没有提供,你将收到错误消息)
Default values
默认值
When you write a function, you can define a default value for each parameter. If an argument is provided in the function call, Python will use the argument. Otherwise, the default value will be used.
- 当你编写一个函数时,你可以为每个参数定义一个默认值。如果在函数调用中提供了参数,Python 将使用该参数。否则,将使用默认值
Using default values can simplify the function calls (you can set the default value to commonly used values)
- 使用默认值可以简化函数调用(你可以将默认值设置为常用值)
To avoid confusion, default values should be listed last in the definition of a function
- 为了避免混淆,默认值应该在函数定义中列在最后
Default values: exampl
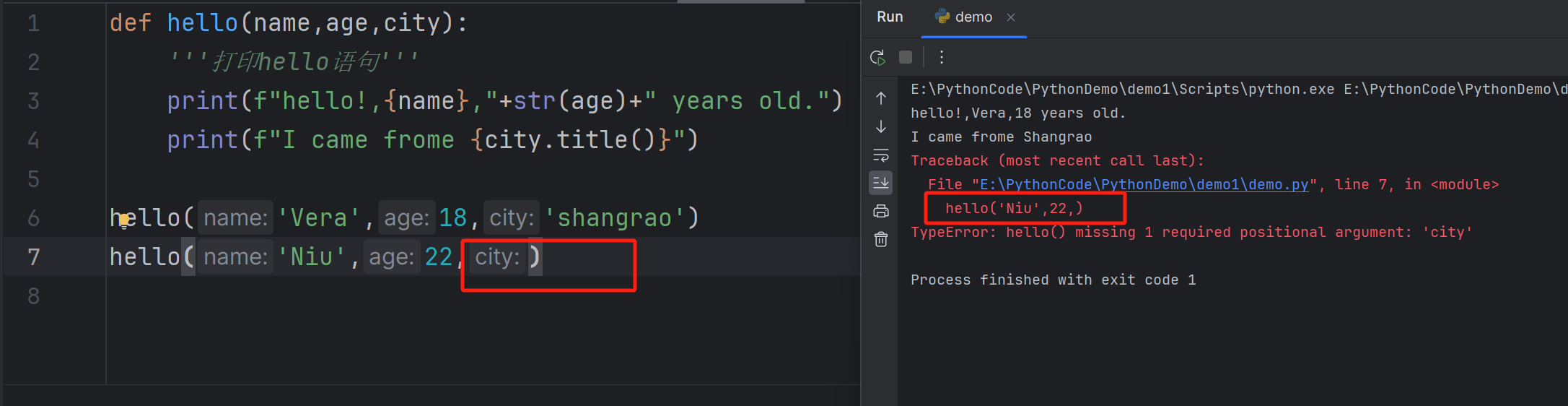
我们在这少穿了一个参数,可以看到python编译器报错了,接下来使用默认参数试一试
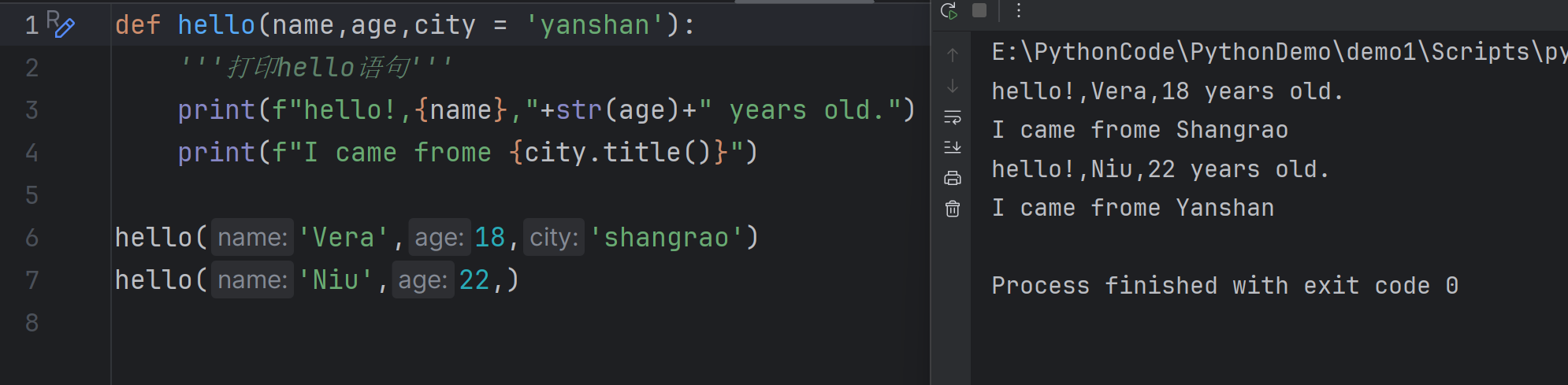
这样子我们即使没有传city形参所对应的入参,也不会报错,因为如果没有入参的话,会默认使用我们的默认参数'yanshan',而如果你传了入参,那么会使用你的入参而不用默认参数
Return values
返回值
A function can process some data and then return a value or set of values rather than display its output
- 一个函数可以处理一些数据,然后返回一个值或一组值,而不是显示其输出
The return statement takes a value from inside a function and sends it back to the line that called the function
return语句从函数内部获取一个值,并将其发送回调用函数的行
1
2
3
4
5def my_abs(x):
if(x>0):
return x
if(x<=0):
return -x
You need to provide a variable to store the returned value when you call a function
- 当你调用一个函数时,你需要提供一个变量来存储返回的值
When a function doesn’t have a return value, Python will return None by default.
- 当一个函数没有返回值时,Python 默认会返回 None。
In the previous example, what will you get from print(student(‘Sabrina’,18))?
- 在之前的示例中,如果你执行
print(student('Sabrina', 18)),你会得到 None。
The remaining code lines after the return statement will be ignored
- return 语句后的剩余代码行将被忽略
Making an argument optional
使一个参数变成可选
You may need to make an argument optional so that people can choose to provide extra information. You can set the default value of a parameter to an empty string to achieve that
你可能需要将一个参数设置为可选,这样人们就可以选择提供额外的信息。你可以将参数的默认值设置为空字符串来实现这一点。
1
2
3
4
5
6
7
8
9
10
11def get_all_name(first_name,last_name,middle_name=''):
'''return all name'''
# 如果middlename存在,if 会判断为真
if middle_name:
all_name = f"{first_name} {middle_name} {last_name}"
else:
all_name = f"{first_name} {last_name}"
return all_name
man = get_all_name('潇','哥','洒')
print("all name of man is ",man)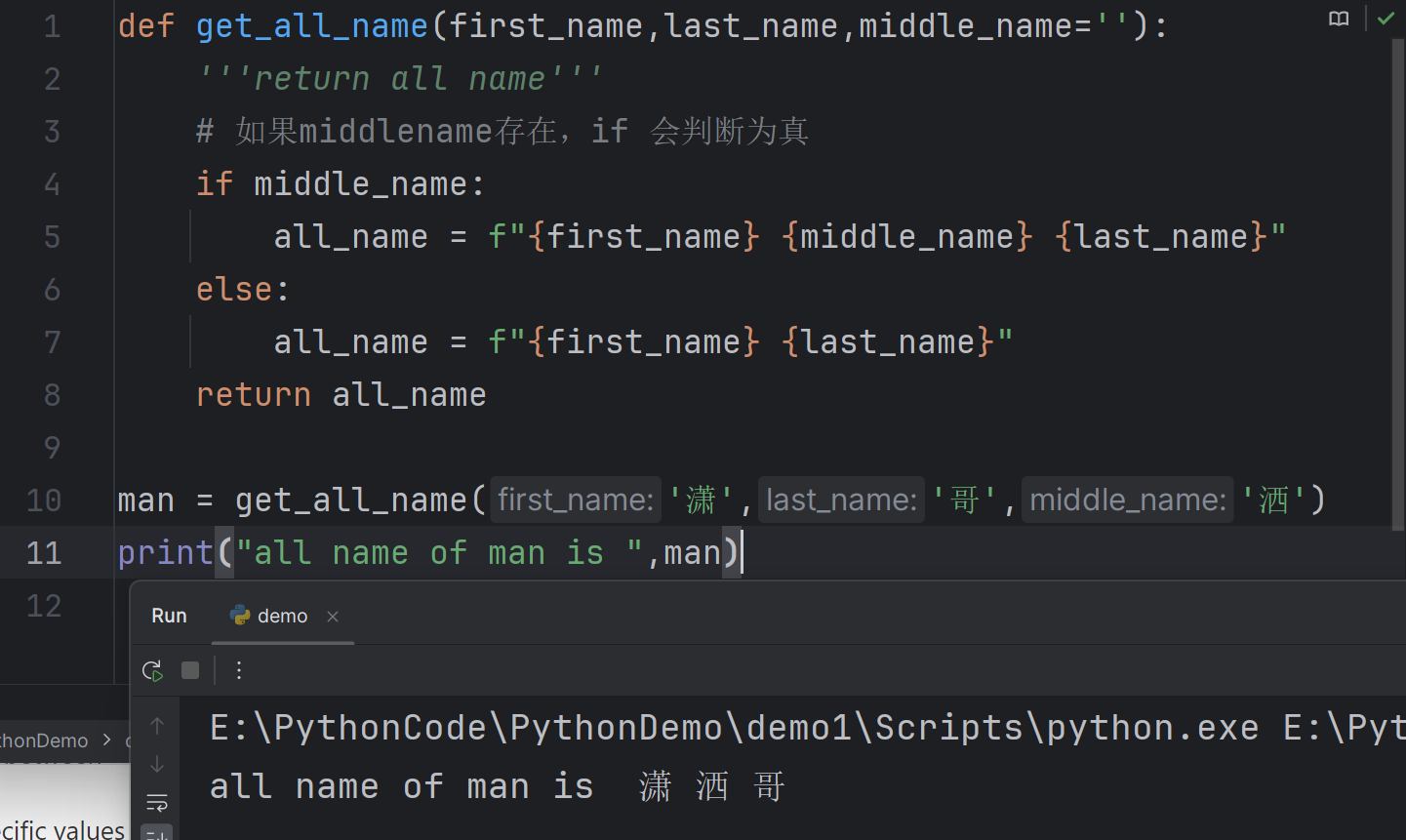
Arbitrary number of arguments
When you don’t know ahead of time how many arguments a function needs to accept, Python allows you to collect an arbitrary number of arguments
- 当你事先不知道一个函数需要接受多少个参数时,Python允许你收集任意数量的参数
You only need to put an asterisk in front of the parameter in the definition
- 你只需要在定义中的参数前面加上一个星号
For example, you want to define a function to calculate the sum of some numbers, but you don’t know how many numbers the users wants to calculate
例如,你想定义一个函数来计算一些数字的总和,但你不知道用户想要计算多少个数字
1
2
3
4
5
6
7
8
9
10
11def my_sum(*nums):
i = 0
for n in nums:
i = i+n
return i
sum = my_sum(1,2,3,4,5)
print(sum)
#运行结果
15
The asterisk in the parameter tells Python to make an empty tuple called numbers to collect the values into it.
- 参数中的星号告诉Python创建一个名为numbers的空元组,用于收集值
You can then call the function with a variable amount of arguments
- 然后你可以用不同数量的参数来调用函数。
Or you can define a tuple or list containing all the values you need to use, and then pass the tuple or list to the function (also with asterisk in front of the variable name of the tuple or list).
或者你可以定义一个包含所有需要使用的值的元组或列表,然后将元组或列表传递给函数(同样在元组或列表的变量名前面加上星号)
1
2
3
4
5
6
7
8
9
10
11def my_sum(*nums):
i = 0
for n in nums:
i = i+n
return i
nums=range(1,6)
print(my_sum(*nums))
#运行结果
15
Alternatively, you can define the function with one parameter, then you pass a tuple or list to the function (without the asterisk)
- 另外一种方法是,你可以定义一个带有一个参数的函数,然后将一个元组或列表传递给该函数(不带星号)
Or you can call the function with a tuple or list being the argument. mysum([1, 2, 3, 4])
或者你可以用一个元组或列表作为参数来调用该函数。例如,
mysum([1, 2, 3, 4])1
2
3
4
5
6
7
8
9
10
11def my_sum(nums):
i = 0
for n in nums:
i = i+n
return i
nums=[1,2,3,4]
print(my_sum(nums))
#运行结果
10看到这里你也许会有些疑惑?为什么又是带 * 号,又是不带 * 号?传的参数又有些不一样?这里面究竟有什么区别?我该如何理解?
这是因为在Python中,可以通过两种方式传递可变数量的参数给一个函数,而这两种方式有着微妙的区别。
带有 * 号的参数(*args):
- 当你在函数定义中使用带有 * 号的参数时,它将收集所有的位置参数并将它们放入一个元组中。
- 你可以调用该函数,并在调用时提供任意数量的位置参数,这些参数将被收集到一个元组中。
- 例如:
mysum(1, 2, 3, 4),这些参数将被收集到名为numbers的元组中:numbers = (1, 2, 3, 4)。
不带 * 号的参数:
- 如果你定义一个函数只带有一个参数,但在调用时传递了一个元组或列表,Python会将整个元组或列表视为单个参数,而不会展开它们。
- 例如:
mysum([1, 2, 3, 4]),这个列表将作为一个整体传递给函数,而不是被解包成多个参数。
你可以根据你的需求选择使用哪种方式。如果你想要一个接受任意数量位置参数的函数,并将它们收集到一个元组中,你应该使用带有 * 号的参数。如果你想要将一个列表或元组作为单个参数传递给函数,你应该在调用时省略 * 号。
Mixing positional and arbitrary argument
混合使用位置参数和任意数量参数
If a function needs to accept different kinds of arguments, the parameter accepting an arbitrary number of arguments must be placed last in the function definition.
- 如果一个函数需要接受不同种类的参数,接受任意数量参数的参数必须放在函数定义的最后
Python will match positional and keyword arguments first and then collects remaining arguments in the final parameter. Mixing positional and arbitrary arguments
- Python会先匹配位置参数和关键字参数,然后将剩余的参数收集到最后一个参数中。 混合使用位置参数和任意数量参数
In the following example, each pizza has a size and an arbitrary number of toppings
在下面的示例中,每杯奶茶都有一个大小和任意数量的配料。
1
2
3
4
5
6
7
8def make_tea_milk(size,*choice):
""" 选择要的大小以及配料及其他选项 """
print(f"\n做一个 {size} 的奶茶,加以下小料:")
for c in choice:
print(f"- {c}")
make_tea_milk('大杯','布丁','西米露')
make_tea_milk('中杯',)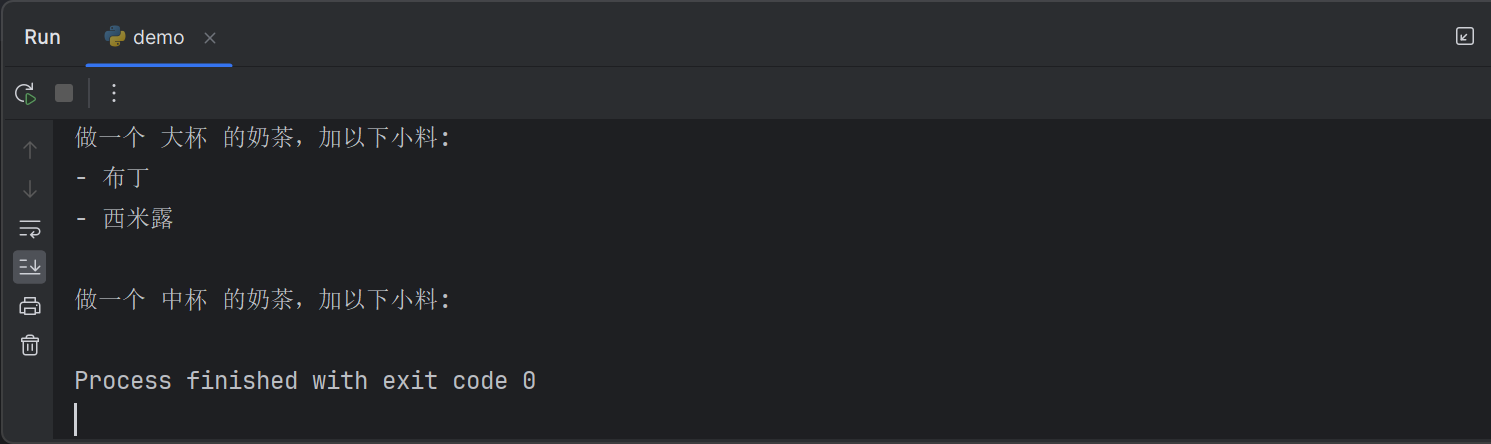
Arbitrary keyword argumens
任意关键字参数
When you want to pass a variable number of keyword arguments to a function, you can use the arbitrary keyword argument (**kwargs syntax) that accepts as many key-value pairs as the calling statement provides
- 当你想要向函数传递可变数量的关键字参数时,你可以使用任意关键字参数(
**kwargs语法),它接受调用语句提供的任意数量的键-值对。
This happens often when your function works with a dictionary.
- 这种情况经常发生在你的函数与字典一起工作时。
Arbitrary keyword argument
- 任意关键字参数
For example, you want to create and then return a dictionary.
- 例如,你想要创建并返回一个字典。
In this example, the double asterisks in user_info allows Python to create an empty dictionary that called user_info and pack the name-value pairs into this dictionary (in this case, location - Princeton as a pair)
在这个例子中,**user_info 中的双星号允许 Python 创建一个名为 user_info 的空字典,并将键-值对打包到这个字典中(在这种情况下,位置 - Princeton 作为一个键值对)
1
2
3
4
5
6def create_user_info(**kwargs):
return kwargs
# 示例调用
user_info = create_user_info(name='Alice', age=25, city='New York')
print(user_info)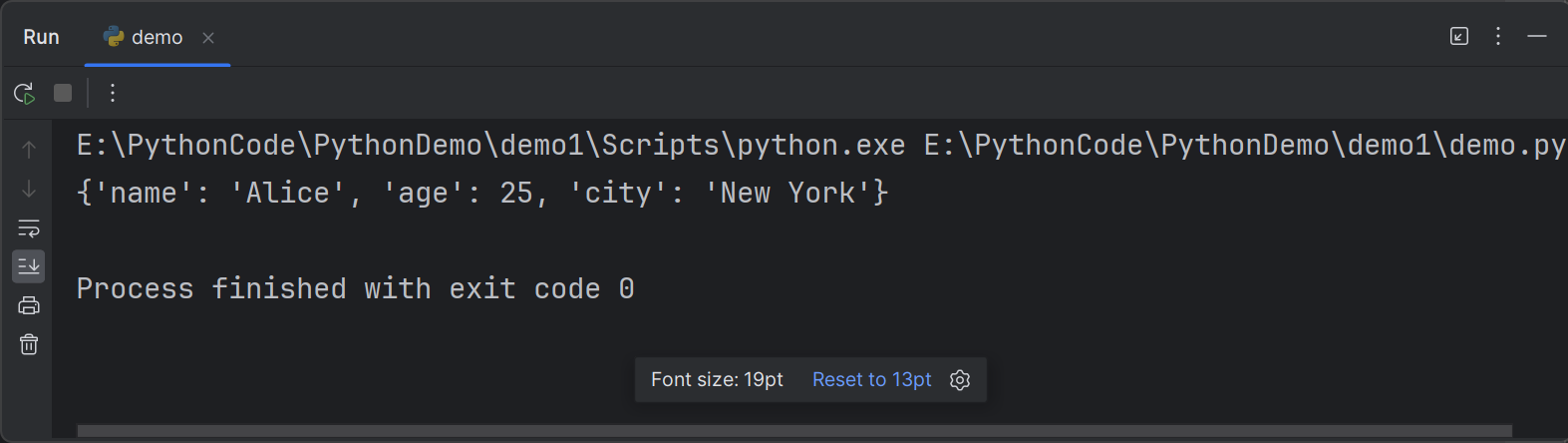
You can also pass an existing dictionary to the function (similarly by adding at the beginning of the dictionary name)
你也可以将一个已存在的字典传递给函数(类似地,在字典名前面添加 **)
1
2
3
4
5
6
7
8def print_info(**info):
for key,value in info.items():
print(f"{key} is {value}")
# 定义一个字典
user_info = {'name': 'Alice', 'age': 25, 'city': 'New York'}
# 将字典解包并传递给函数
print_info(**user_info)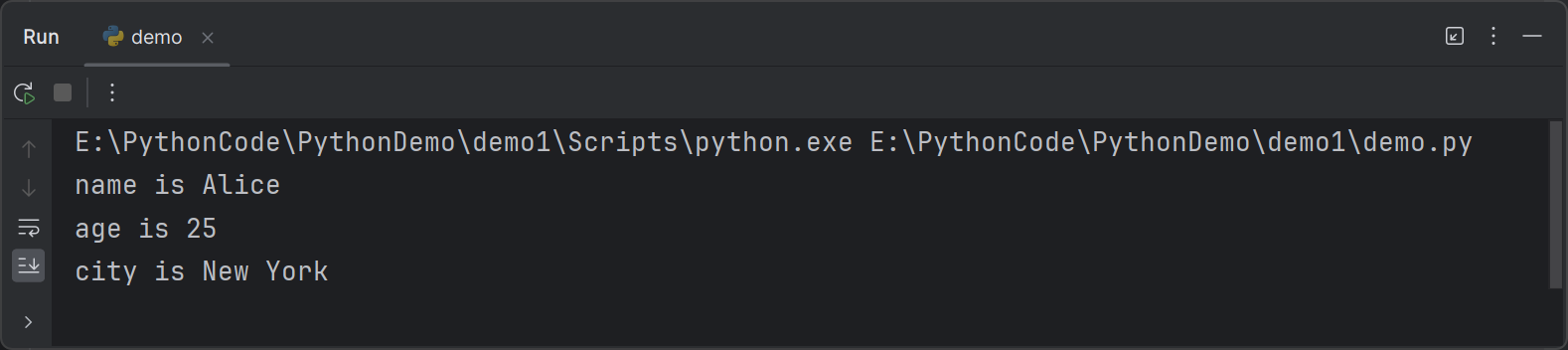
字典中有
key和value,在本例中,例如 ‘name’ 既是key,而这个key对应的value是 ‘Alice’ ,以此类推
Think about the student function earlier on, if you don’t know in advance what kind of information about that student will be passed to the function, then you could use arbitrary keyword arguments
- 想想之前的 student 函数,如果你事先不知道会传递给函数的学生信息的种类,那么你可以使用任意关键字参数
Using a function with a while loop
在 while 循环中使用函数
You can use functions with all other knowledge you have learned about Python. For example, you can define a function with a while loop
- 你可以将你学到的所有关于 Python 的知识与函数结合使用。例如,你可以定义一个带有 while 循环的函数。
Define a function to calculate a number to a power
定义一个用于计算一个数的幂的函数
1
2
3
4
5
6
7
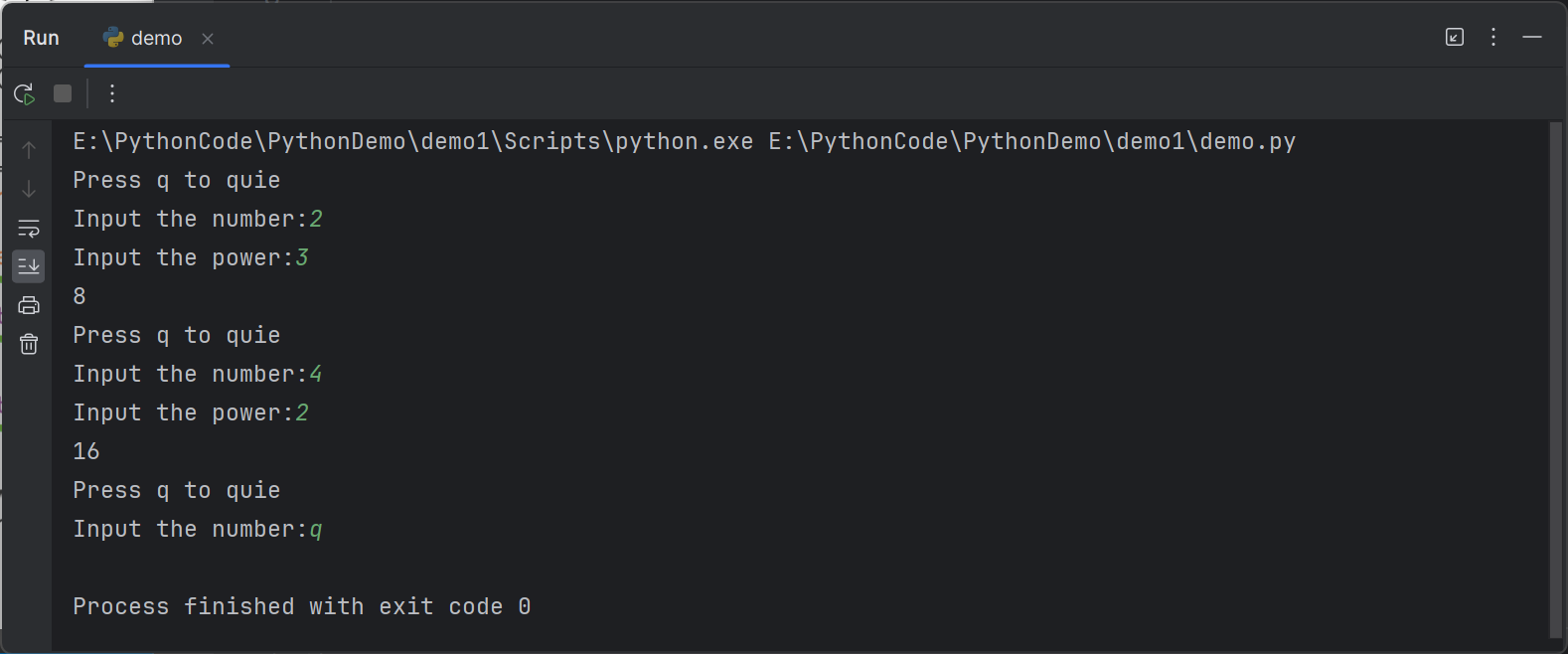
8def power(x,n):
s = 1
while n > 0:
s = s * x
n = n -1
return s
print(power(5,3))这段代码定义了一个名为
power的函数,用于计算一个数的幂。函数接受两个参数x和n,其中x是底数,n是指数。在函数体内部,首先初始化一个变量
s为 1,用于保存计算结果。然后通过 while 循环,当指数n大于 0 时,执行以下操作:- 将
s乘以底数x,更新s的值。 - 将指数
n减去 1,更新n的值。
这样,每次循环都相当于将底数
x乘以s,直到指数n减少到 0 为止。最后,函数返回计算结果s。总而言之,这个函数实现了计算一个数的指数幂的功能。
- 将
Use a while loop with a function
1 | def power(x,n): |
Mixing different arguments (* extra)
函数定义中同时使用不同类型的参数
You can pass different types of arguments to a function, but it should be in the following order: positional arguments, default arguments, arbitrary number of arguments, arbitrary keyword arguments
- 你可以向函数传递不同类型的参数,但应按照以下顺序排列:位置参数、默认参数、任意数量参数、任意关键字参数。
- “Mixing different arguments” 意味着在函数定义中同时使用不同类型的参数,例如位置参数、任意数量参数(*args)和任意关键字参数(**kwargs)等。这种情况下,函数可以接受各种不同形式的输入,并以灵活的方式进行处理。
Define a function like the following example
定义一个类似以下示例的函数
1
2
3
4
5
6
7
8def example_function(a, b, *args, **kwargs):
print("a:", a)
print("b:", b)
print("Extra positional arguments:", args)
print("Extra keyword arguments:", kwargs)
# 调用函数
example_function(1, 2, 3, 4, c=5, d=6)在这个示例中,函数
example_function接受两个位置参数a和b,任意数量的额外位置参数args和任意数量的额外关键字参数kwargs。当我们调用函数时,1被分配给a,2被分配给b,3和4被收集到args中,而c=5和d=6被收集到kwargs中。
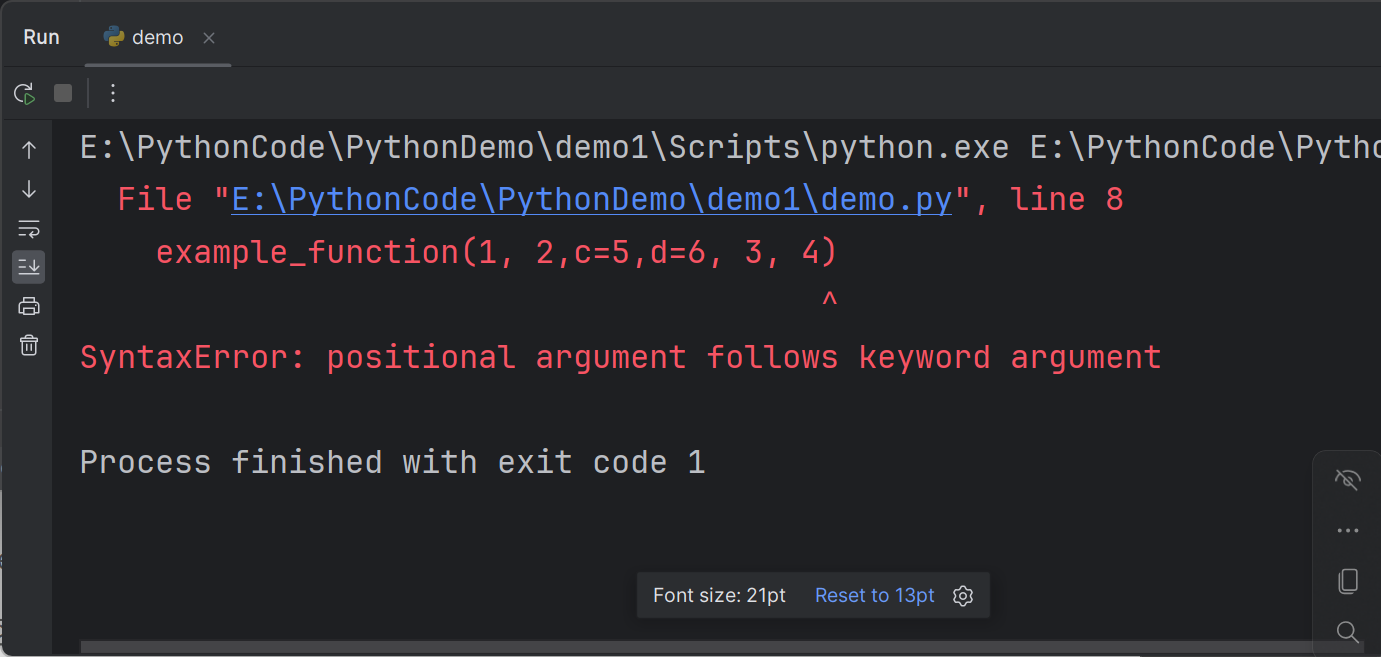
If you want to swap the positions of *args and **kw, you will get an error message. Mixing different arguments (* extra)
如果你想要交换
*args和**kwargs的位置,你会收到一个错误消息。 混合不同类型的参数(*额外)1
example_function(1, 2,c=5,d=6, 3, 4)
Try different ways of calling the following function and see what outputs you will get
尝试以不同的方式调用以下函数,并查看你会得到什么输出
1
2
3
4
5
6
7
8
9
10
11def example_function(a, b, *args, **kwargs):
print("a:", a)
print("b:", b)
print("Extra positional arguments:", args)
print("Extra keyword arguments:", kwargs)
# 调用函数
example_function(1, 2)
example_function(1,2,c=3)
example_function(1,2,3,'a','b')
example_function(1,2,3,'a','b',x=99)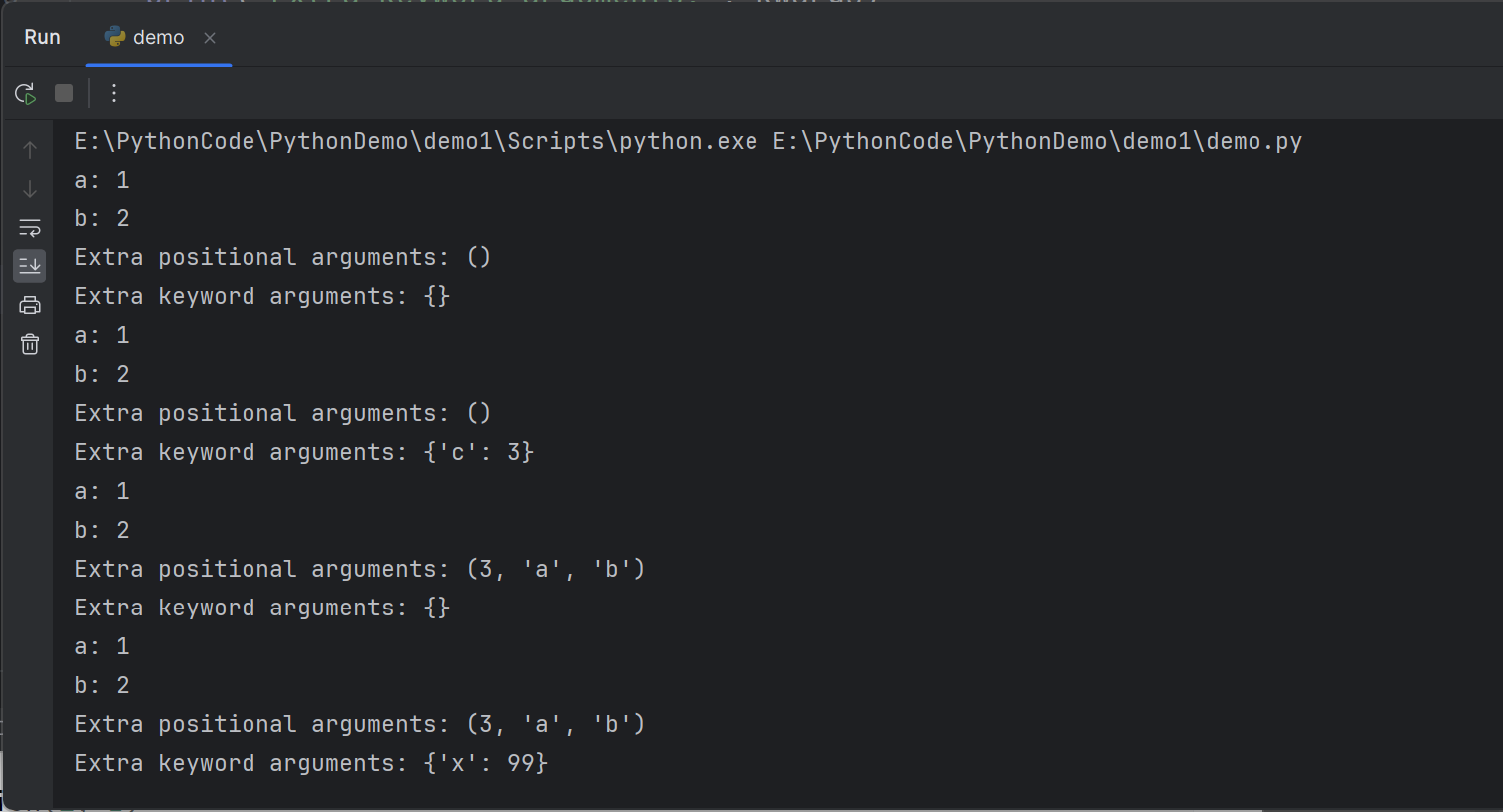
Recursion * (extra)
递归 *(额外)
When a function calls itself, it is called Recursion.
- 当一个函数调用自身时,这被称为递归。
A scenario: someone had a dream, in that dream he had another dream, in that dream he had yet another dream, and that goes on.
- 一个场景:有人做了一个梦,在那个梦里他又做了一个梦,然后在那个梦里他又做了一个梦,如此往复。
It could be very powerful, but avoid writing a function which never terminates
- 这可能非常强大,但要避免编写一个永远不会终止的函数。
For example, if you call the above function dream(), it will keep printing ‘Dreaming’
例如,如果你调用上面的函数 dream(),它将不断地打印 ‘Dreaming’。
1
2
3
4
5def dream():
print('Dreaming...')
dream()
dream()现在的编译器在当你过多的递归时候,会报错
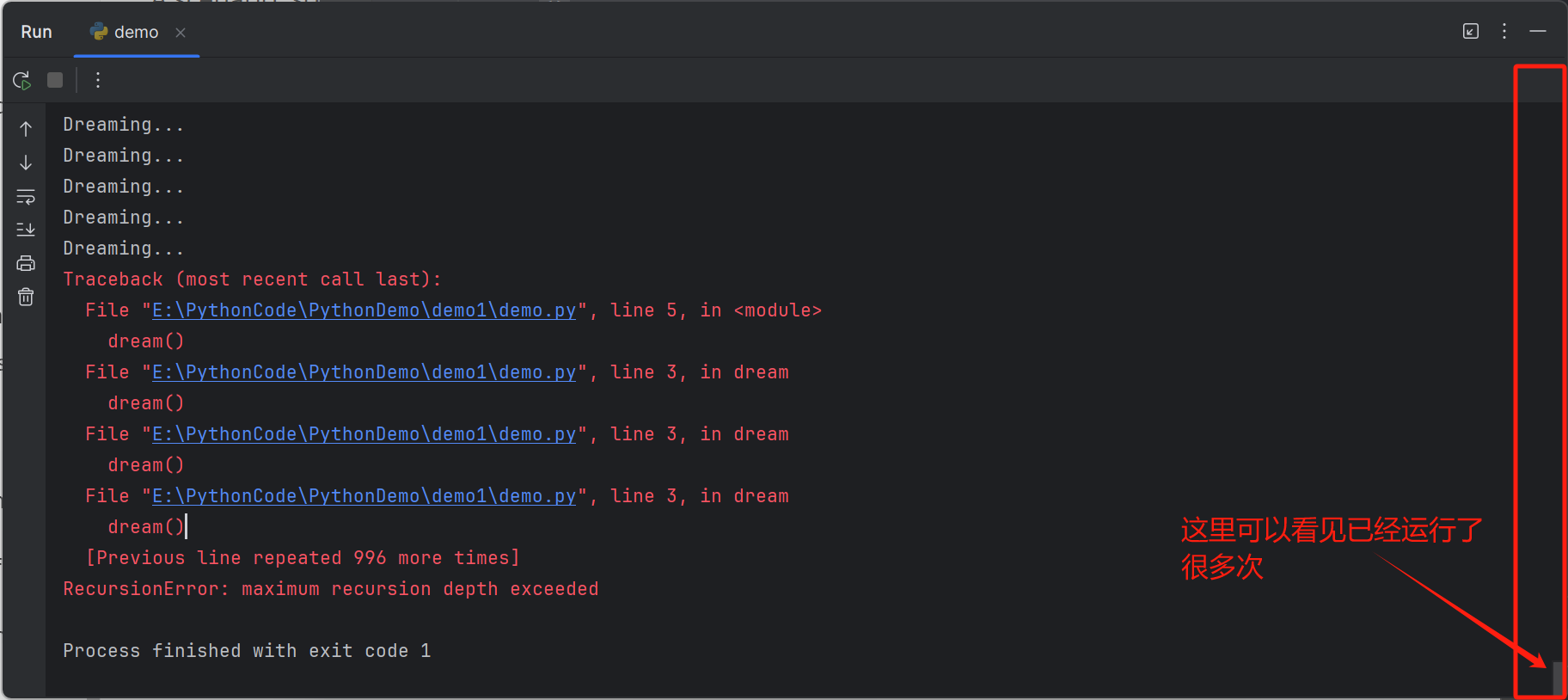
SMA-w9_1
Modules and file handling
Introduction to modules
Functions allow you to separate blocks of code from your main programme and focus on the main programme.
- 函数允许你将代码块从主程序中分离出来,使你可以专注于主程序。
You can store your functions in a separate file called a module. Then the functions can be reused in different programmes when the module is imported.
- 你可以将函数存储在一个名为模块的单独文件中。然后,当导入模块时,这些函数可以在不同的程序中被重用。
Define a function to remind students to select courses (the name of the Division will be the parameter
定义一个函数,用来提醒学生选择课程(参数是学部名称)
1
2
3
4
5
6
7
8
9
10def selection(division):
'''Remind students to select their MR courses'''
courses = []
print('You are requires to select there major courses'+
f'from {division} for this')
for i in range(3):
courseSelected = input(f'Please enter course {i+1}:')
courses.append(courseSelected)
print(courses)
return (courses)
Save the function as a module called course.py
A module can contain lots of functions. We can define another function to print out courses in a nicer format. This function can be saved in the same module
一个模块可以包含许多函数。我们可以定义另一个函数,以更好的格式打印课程信息。这个函数可以保存在同一个模块中。
1
2
3
4
5def output(selected):
'''Print out the courses a student has selected'''
print('You have selected the following courses:')
for myCourse in selected:
print(f'\t{myCourse}')
Importing a module
Before you import a module saved on your computer, the module has to be stored in the current working directory of Python. You could use the built-in module of OS to check your current working directory
在导入保存在计算机上的模块之前,该模块必须存储在Python的当前工作目录中。你可以使用内置的OS模块来检查你的当前工作目录。
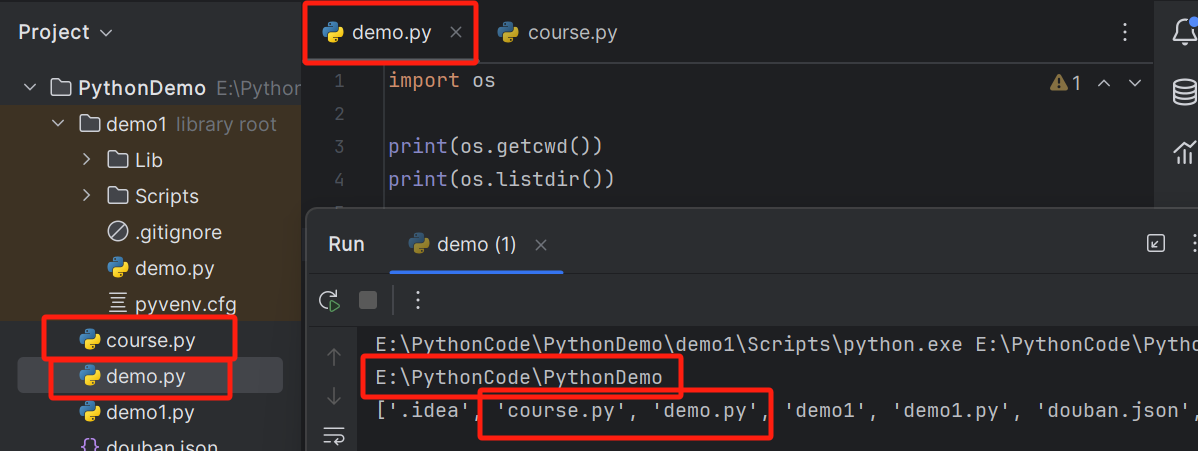
第一个打印出当前文件所在的路径,第二个打印出当前文件路径下的所有文件,可以看到,我们之前写的 course.py是存在于当前demo.py的文件路径的目录下的
You can use os module to change your current current working directory by providing the full file path you want to use. The easiest way for Mac user is to select the folder -> right click -> press and hold the option key -> choose Copy “File-name” as Pathname, then paste the file name to os.chdir().
- 你可以使用os模块通过提供想要使用的完整文件路径来更改你的当前工作目录。对于Mac用户,最简单的方法是选择文件夹 -> 右键单击 -> 按住Option键 -> 选择“复制“文件名”作为路径”,然后将文件名粘贴到os.chdir()中。
For windows users, press and hold the Shift Key and right-click on a folder, then click the Copy as path option from the Windows context menu.
- 对于Windows用户,按住Shift键右键单击文件夹,然后从Windows上下文菜单中选择“复制为路径”选项。
Or you could change your current working directory by changing the setting in Spyder (see next slide), but you may have to restart your Spyder before the change works
- 或者你可以通过在Spyder中更改设置来更改你的当前工作目录(参见下一张幻灯片),但是在更改生效之前,你可能需要重新启动你的Spyder。
Importing a module
Providing that you have downloaded course.py from iSpace and saved it in your current working directory, you can then import it
假设你已经从iSpace下载了course.py文件,并将其保存在你的当前工作目录中,你就可以导入它了。
1
2
3
4import course
my_course = course.selection('DHSS')
print('the following students have bee enrolled:')
print(my_course)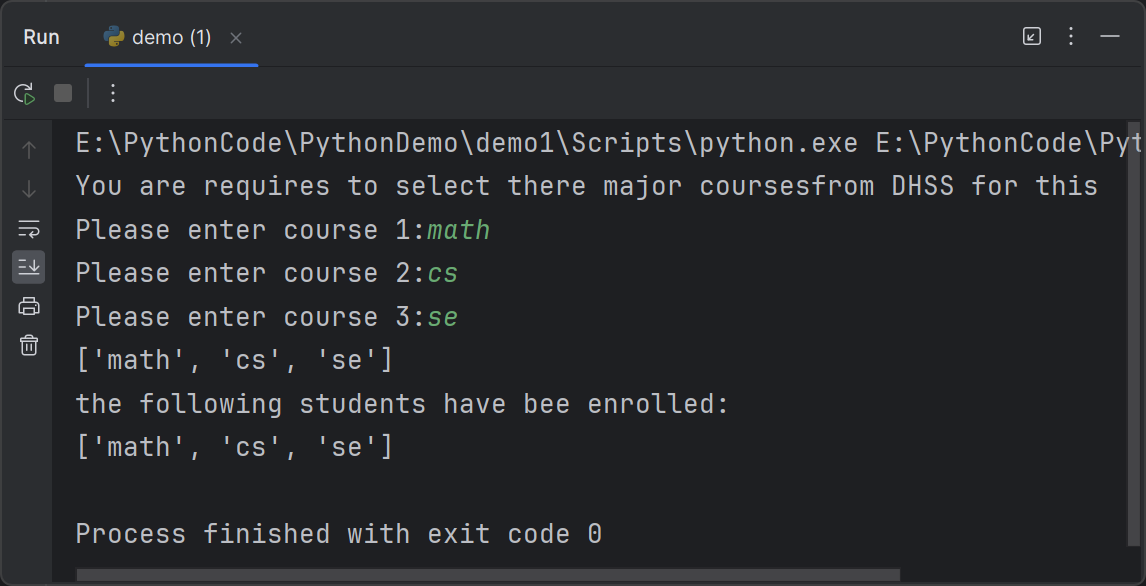
To call a function from an imported module, enter the name of the module, followed by the name of the function, separated by a dot
要从一个导入的模块中调用函数,输入模块的名称,然后是函数的名称,二者之间用点号分隔。
1
2import course
my_course = course.selection('DHSS')
The line of importing a module tells Python to open the module file and copy all the functions from it into the programme
- 导入模块的语句告诉Python打开模块文件,并将其中的所有函数复制到程序中。
We can then use all of its functions after you having imported the module
- 在导入模块后,我们就可以使用它的所有函数。
You can use dir() to check all the functions contained in a module
你可以使用
dir()函数来检查模块中包含的所有函数。1
2import course
print(dir(course))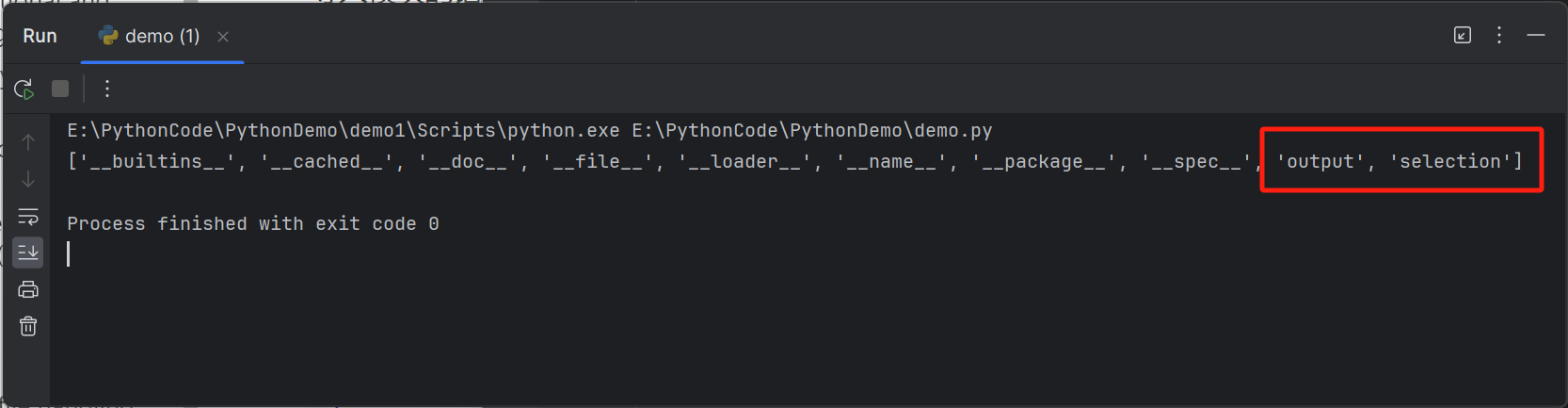
python中的函数命名应该是跟前面的那些一样,所以正确的规范应该是
__selection__
Importing specific functions
导入特定函数
You can choose to import a specific function from a module
你可以选择从一个模块中导入特定的函数:
from module_name import function_name
You can also choose to import a few functions from a module by separating each function’s name with a comma
你还可以选择从一个模块中导入几个函数,通过用逗号分隔每个函数的名称。
1
2from course import selection,output
my_course = selection("DHSS")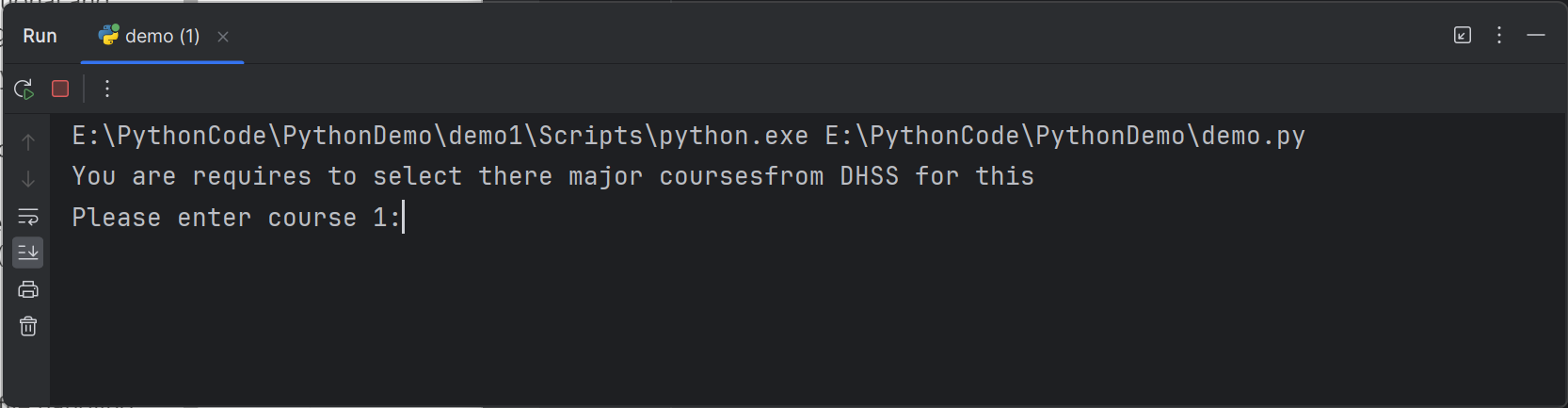
With this syntax, you don’t need to use the dot notation when you call a function
- 使用这种语法,当你调用一个函数时,就不需要使用点符号。
Using alias
使用别名
When you import functions from a module, you need to avoid their names conflicting with an existing name in your programme.
- 当你从一个模块中导入函数时,你需要避免它们的名称与程序中现有的名称发生冲突。
When this might be the case or just because the function name is long, you could use a short, unique alias for the function.
- 当可能发生这种情况时,或者只是因为函数名称太长,你可以为函数使用一个简短、唯一的别名。
You can also provide an alias to a module.
你也可以为模块提供一个别名。
1
2import course as c
c.selection('DHSS')
You can import all functions in a module by using asterisk (*)
你可以使用星号 (*) 来导入一个模块中的所有函数
1
from course import *
In this case, Python will copy all the functions from the module into your programme file. You can then use call each function by name without using the dot notation.
- 在这种情况下,Python会将模块中的所有函数复制到你的程序文件中。然后,你可以按名称调用每个函数,而不需要使用点符号。
However, when there are several existing functions or variables with the same name in your programme, Python will overwrite the functions.
- 然而,当你的程序中存在几个同名的现有函数或变量时,Python会覆盖这些函数
The best approach is to import the functions you want or import the entire module and use the dot notation
- 最好的方法是只导入你需要的函数,或者导入整个模块并使用点符号。
Styling functions
Every function should have a comment that explains concisely what the function does by using the docstring format
- 每个函数都应该有一个注释,使用文档字符串格式简要解释函数的功能。
If your program or module has more than one function, you can separate each by two blank lines
- 如果你的程序或模块有多个函数,你可以用两个空行将它们分开
All import statements should be written at the beginning of a file
- 所有的导入语句应该写在文件的开头。
Working with files
处理文件
It is important to be able to open and save data to a file in your programme, especially for data analysis.
- 处理文件是很重要的,能够在你的程序中打开和保存数据到文件中,尤其是对于数据分析。
A common file type is text files.
- 一个常见的文件类型是文本文件。
Exercise: create a text file (Notepad or TextEdit) with the following information as weather.txt
练习:创建一个文本文件(使用记事本或TextEdit),文件名为weather.txt,内容如下:
1
Working with files
Create a Python programme and save it to the same directory, then run the programme
- 创建一个Python程序并保存到同一个目录下,然后运行程序。
Alternatively you can save your txt file in your current Python working directory, then you type in the command in your Python IDE to work with the file
- 或者你可以将txt文件保存在当前Python工作目录中,然后在Python IDE中输入命令来操作文件。
The open() function requires the file name as the argument. It will return an object representing the file you want to work with.
open()函数需要文件名作为参数。它会返回一个表示你要处理的文件的对象。
Then you can use read() method to read the entire contents of the file and store it as one long string in the ‘contents’ variable.
- 然后你可以使用read()方法来读取文件的全部内容,并将其存储为一个长字符串,赋值给‘contents’变量。
Task: check the data type of ‘contents’ variable; use dir to check the methods related to the ‘weather_info’ object.
- 任务:检查‘contents’变量的数据类型;使用dir检查与‘weather_info’对象相关的方法。
It is important to close the file after you finish working with it to avoid the potential problem of lost data or corrupted file. But the keyword ‘with’ closes the file automatically once the the access to it is no longer needed.
- 在完成文件操作后关闭文件是很重要的,以避免数据丢失或文件损坏的潜在问题。但是关键字‘with’会在不再需要访问文件时自动关闭文件。
When the file you want to work with is stored in a subdirectory of current Python working directory or in a completely different directory, you will need to give Python the file paths (relative file path or absolutely file path)
- 当你要处理的文件存储在当前Python工作目录的子目录中或完全不同的目录中时,你需要给Python提供文件路径(相对文件路径或绝对文件路径)。
Using relative file path (for subdirectory)
使用相对文件路径(对于子目录)
1
2
3
4
5
6
7
8
9with open('subdirectory/filename.txt') as file_object:
Using absolute file path
- 使用绝对文件路径
```python
file_path = 'C:/Users/Administrator/filename.txt'
with open(file_path) as file_object:
You need to use quotes for the file path
- 你需要使用引号引用文件路径。
If you need to examine each line of the file (to look for certain information or to modify the text), you can use a for loop to achieve that.
如果你需要检查文件的每一行(查找特定信息或修改文本),你可以使用for循环来实现。
1
2
3with open('weather.txt') as fileobject:
for line in fileobject:
print(line)
You will get an output (with blank lines) like the following format
你将会得到一个输出(带有空行),格式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31Shantou, Cloudy
Shenzhen, Sunny
Guangzhou, Sunny
You will get an extra blank line, because an invisible newline character is at the end of each line in the text file and the print() function will also add a new line when it finishes.
- 你会得到一个额外的空行,因为文本文件中的每一行末尾都有一个不可见的换行字符,并且print()函数在结束时也会添加一个新行
In order to remove the extra blank lines, you can modify the code to
- 为了去除额外的空行,你可以修改代码为
` print(line.rstrip()) `
When you use ‘with’, the file object returned is only available inside the ‘with’ block. You could store its content in a string by using read() or in a list by using the readlines() method
- 当你使用‘with’时,返回的文件对象仅在‘with’块内可用。你可以使用read()方法将其内容存储在一个字符串中,或使用readlines()方法存储在一个列表中。
The output is a list with newline characters at the end.
- 输出是一个带有换行字符的列表。
### Writing to a file
If you want to write text to a file, you need to call open() function with an additional argument ‘w’ telling Python that you want to write to the file
- 如果你想要向文件中写入文本,你需要调用`open()`函数,并在第二个参数中加入`w`告诉Python你想要写入文件。例如:
```python
with open('programming.txt', 'w') as file:
file.write('我喜欢Python课程')
You can open a file in read mode (‘r’), write mode (‘w’), append mode (‘a’), or a mode that allows both reading and writing to the file (‘r+’). The default mode is read-only if you don’t give an argument. Writing to a file
- 你可以用
r模式打开文件(只读模式),w模式(写模式),a模式(追加模式),或者一个同时允许读和写的模式(r+)。如果你不给出参数,默认模式是只读的。
The open() function automatically creates the file if it doesn’t already exist. However, when you use w mode, Python will erase the contents of the file if it does exist (so be careful)
open()函数会自动创建文件,如果文件不存在的话。但是,当你使用w模式时,如果文件已经存在,Python会擦除文件内容(所以要小心)。
Writing multiple lines: write() function doesn’t add any newline characters to the text you write. You should include newline characters in your call to write() so that the output appears on separate lines
写入多行文本:
write()函数不会在你写入的文本后添加换行符。你应该在write()的调用中包含换行符,这样输出会显示在不同的行上。例如:1
2
3with open('programming.txt', 'w') as file:
file.write('I like the Python course.\n')
file.write('Mr. Yun is a cool (or cruel) guy.\n')
Exercise: create a text file in Python, write two lines of texts. Then open the text file in file management and check its content.
- 练习:在Python中创建一个文本文件,写入两行文本。然后在文件管理器中打开文本文件,检查其内容。
If you want to add content to a file instead of writing over existing content, you can open the file in append mode (‘a’). If the file doesn’t exist, Python will create an empty file for you.
如果你想要添加内容而不是覆盖已有内容,你可以用追加模式(
a)打开文件。如果文件不存在,Python会为你创建一个空文件。例如:1
2
3filename = 'programming.txt'
with open(filename, 'a') as file:
file.write('我在Python编程课程中表现得很好。\n')
JSON file
If you need to store information in data structures such as list and dictionaries, JSON data format will be a good option.
- 如果你需要存储列表和字典等数据结构中的信息,JSON数据格式是一个不错的选择。
JSON data format can be easily shared between people working in different programming languages.
- JSON 数据格式可以在不同编程语言之间轻松共享。
You will need to import JSON module first, and then use json.dump() to store and json.load() to read the data.
你需要先导入 JSON 模块,然后使用
json.dump()来存储数据,json.load()来读取数据。例如:1
2
3
4
5
6
7
8import json
numbers = list(range(2, 11, 2))
print(numbers)
filename = 'evennum.json'
with open(filename, 'w') as f_obj:
json.dump(numbers, f_obj)
Open evennum.json file and read the data, you can see that the data type is the same as what you have saved earlier.
1 | import json |
Exercise: Define a function to record the student name and the four courses they selected for a semester. Then save the course information in a json file with student name being the file name. Then write a programme to read the json file and print out the list of courses
练习:定义一个函数来记录学生的姓名和他们选择的四门课程。然后将课程信息保存在一个以学生名字命名的JSON文件中。接着编写一个程序来读取JSON文件,并打印出课程列表。
写入 json
1
2
3
4
5
6
7
8
9
10
11
12
13
14import json
def __student_course__():
courses = []
student_name = input('please enter name:')
for i in range(0,4):
course = input(f'please enter course{i+1}:')
courses.append(course)
filename = f'{student_name}.json'
with open(filename, 'w') as f_obj:
json.dump(courses, f_obj)
__student_course__()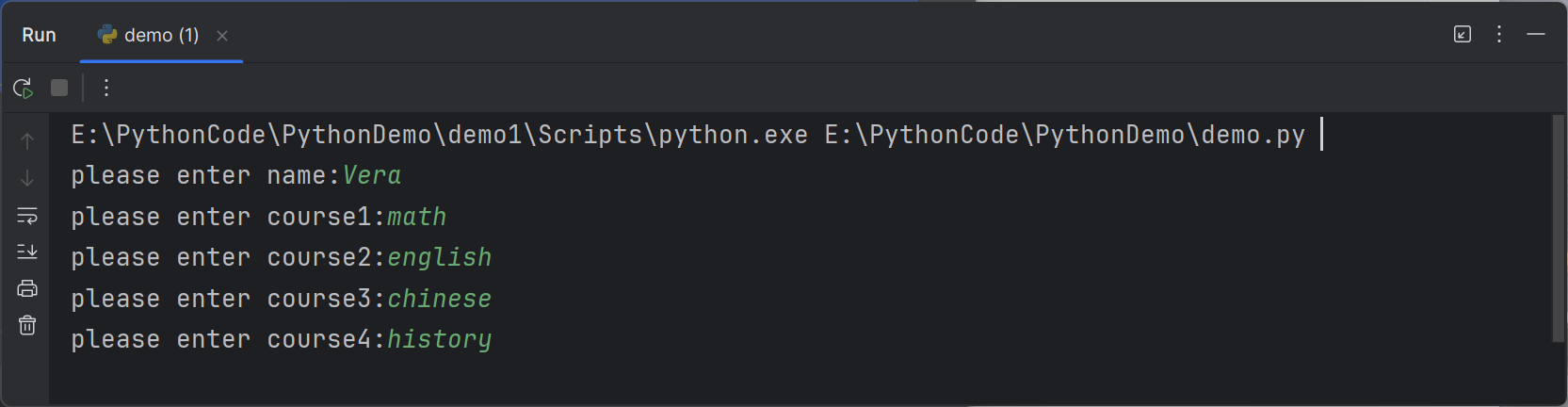
读取 json
1
2
3
4
5
6
7
8import json
student_name = input('which student do you want to see?:')
filename = f'{student_name.title()}.json'
with open(filename) as f_obj:
courses = json.load(f_obj)
print(courses)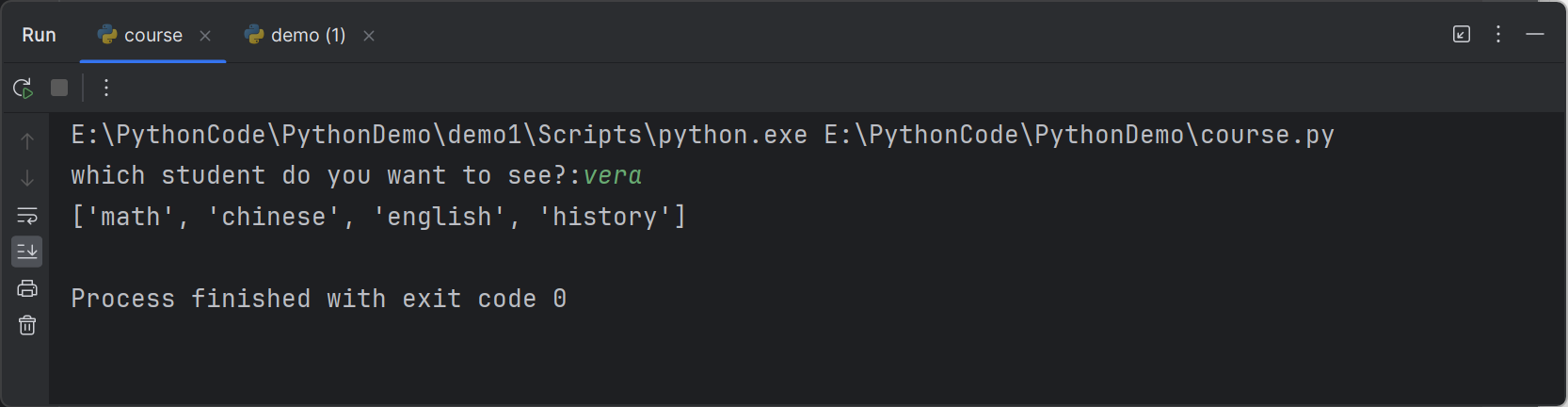
SMA-w10_1
Requests, BeautifulSoup and Web scraping (part 1)
- 请求、BeautifulSoup 和网络爬虫(第一部分)
Urllib and Requests modules
- Urllib 和 Requests 模块
It is common to use Python to scrap data from web
- 用Python从网络上抓取数据是很常见的
From Python 3, urllib and urllib2 have been merged into a new urllib module.
- 从Python 3开始,urllib和urllib2已经合并成一个新的urllib模块
The urllib module is a module built into the Python standard library that allows the user to work with URLs (Uniform Resource Locators)
- urllib模块是Python标准库中内置的一个模块,允许用户处理URL(统一资源定位符)
It is generally recommended to use the Requests module, but you may have to install it.
一般建议使用Requests模块,但你可能需要安装它
urllib模块和requests模块都是用来处理HTTP请求的 Python 库,但它们之间有一些区别:- 功能和易用性:
urllib是 Python 标准库的一部分,提供了处理 URL、发送请求和处理响应的基本功能。它包含了多个子模块,如urllib.request、urllib.parse等,需要更多的代码来完成相同的任务,使用起来相对复杂。requests是一个独立的第三方库,专门设计用来简化发送 HTTP 请求和处理响应。它提供了更简洁、易用的 API,使得发送请求、设置请求头、处理响应等操作更加方便和直观。
- API 设计:
urllib的 API 设计相对较为底层,需要显式地处理请求和响应的各个方面,例如构造请求对象、设置请求头、处理异常等。requests的 API 设计更加高级和友好,提供了一系列简单且一致的方法来发送各种类型的请求,同时还提供了丰富的功能,如自动处理重定向、会话管理、SSL验证、代理等。
- 性能和功能扩展:
- 由于
requests是一个专门优化过的第三方库,通常会比urllib更快,并且提供了更多的功能和扩展,如身份验证、Cookie 管理、上传文件等。
综上所述,虽然
urllib是 Python 标准库的一部分,可以完成基本的 HTTP 请求,但在实际开发中,一般推荐使用requests库,因为它提供了更简洁、易用的 API,并且具有更好的性能和功能扩展。
import requests (if you receive an error message, you will need to install it)
导入requests(如果收到错误消息,你需要安装它)
1
import requests
If you use Python 3.6 and above directly, install the package by using pip install requests
- 如果你直接使用Python 3.6及以上版本,请使用
pip install requests来安装这个包
If you use anaconda, try conda install requests in the command line environment or conda install -c anaconda requests
- 如果你使用的是Anaconda,请尝试在命令行环境中使用
conda install requests来安装,或者conda install -c anaconda requests
Downloading a web page
requests.get() function takes a string of a URL to download and returns a Response object
使用
requests.get()函数接受一个 URL 字符串作为参数来下载网页,并返回一个 Response 对象。1
2
3
4
5
6import requests
res = requests.get('https://www.baidu.com')
res.raise_for_status()
print(type(res))
print(res.text[0:200])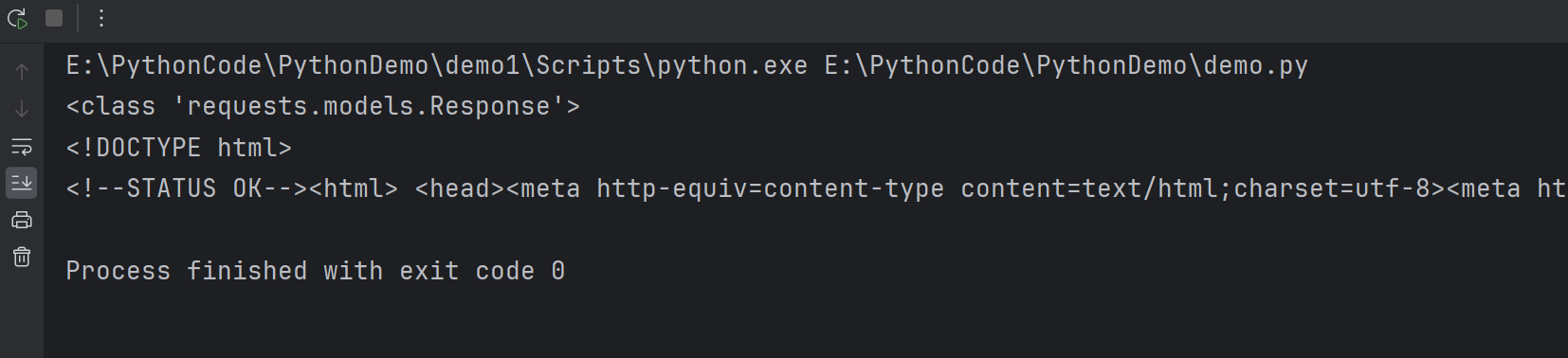
这段代码使用了Python的
requests库来发送一个HTTP GET请求到百度网站(https://www.baidu.com),并获取响应内容。requests.get('https://www.baidu.com'): 这行代码发送一个GET请求到指定的URL(百度网站),并将服务器的响应保存在一个名为res的变量中。requests.get()函数返回一个响应对象,其中包含了服务器的响应信息。res.raise_for_status(): 这行代码检查响应的状态码,如果状态码表明请求成功(即状态码是200),则什么都不做;如果状态码表明请求失败(如404等),则会抛出一个HTTPError异常。这样可以确保我们得到了一个有效的响应,而不是错误页面或其他无效内容。print(type(res)): 这行代码打印res对象的类型,以便我们了解它是什么类型的对象。print(res.text[0:200]): 这行代码打印了响应内容的前200个字符。res.text属性包含了响应的文本内容。通过[0:200]切片操作,我们只打印了前200个字符,以避免打印过多内容。
这段代码的作用是向百度网站发送一个GET请求,并打印出获取的响应内容的前200个字符,同时检查是否有错误发生。
You can check what attributes or methods are available for this object by typing print(dir(res)). You can also check the details of those methods by typing print(help(res))
你可以通过输入
print(dir(res))来查看这个对象的属性或方法。你也可以通过输入print(help(res))来查看这些方法的详细信息。此处输出信息过多,自行尝试
The content and text attributes gives you the content of the response in bytes and unicode respectively.
content 和 text 属性分别以字节和 Unicode 形式给出响应的内容
content属性
content属性返回的是响应内容的字节形式,即以二进制形式表示的原始数据。这个属性通常用于处理非文本数据,比如图片、视频、PDF 等文件,或者需要以二进制形式进行处理的数据。
1
2
3
4
5
6
7
8import requests
response = requests.get('https://images-1318456035.cos.ap-shanghai.myqcloud.com/imgs/20240425204347.png')
image_data = response.content
# 将图片数据保存到文件中
with open('image.jpg', 'wb') as f:
f.write(image_data)
text属性
text属性返回的是响应内容的文本形式,即以 Unicode 编码的字符串。这个属性通常用于处理 HTML 页面、文本文件等文本数据。
1
2
3
4
5
6import requests
res = requests.get('https://www.baidu.com')
res.raise_for_status()
print(type(res))
print(res.text[0:200])
content属性适用于处理二进制数据,而text属性适用于处理文本数据。根据你的需求,选择使用其中的一个来获取响应内容。
You can check the status_code attribute of the Response object to see if the request for the web page succeeded.
你可以检查 Response 对象的
status_code属性来查看网页请求是否成功1
2
3
4
5
6
7
8import requests
res = requests.get('https://www.baidu.com')
res.raise_for_status()
print(type(res))
print(res.text[0:200])
print(res.status_code)
A simpler way to check for success is to call the raise_for_status() method on the Response object.
- 一个更简单的检查成功的方法是在 Response 对象上调用
raise_for_status()方法
This will raise an exception if there was an error and will do nothing if the download succeeded.
- 如果出现错误,这将引发一个异常;如果下载成功,则什么也不会发生。
Fetch an ebook from Project Gutenberg
- 从 Project Gutenberg 获取一本电子书
If the request succeeded, the downloaded web page is stored as a string in the Response object’s text variable.
- 如果请求成功,下载的网页将作为字符串存储在 Response 对象的 text 变量中。
You can use len(res.text) to check the length the string, and can also display part of the string.
你可以使用
len(res.text)来检查字符串的长度,并且也可以显示部分字符串。1
2
3
4
5
6
7
8import requests
res = requests.get('http://www.gutenberg.org/cache/epub/1112/pg1112.txt')
res.raise_for_status()
length = len(res.text)
print(length)
print(res.text[0:200])
You can then save the web page to a file with the open() and write() function.
- 你可以使用
open()和write()函数将网页保存到文件中
But you need to write binary data instead of text data in order to maintain the Unicode encoding of the text, so use wb as the second argument to open()
但是你需要写入二进制数据而不是文本数据,以保持文本的 Unicode 编码,所以在
open()的第二个参数中使用wb。wb是用于以二进制写入模式打开文件的文件模式w表示写入模式,用于指示打开文件以进行写入操作。b表示二进制模式,用于指示打开文件以二进制模式进行读取或写入
You will receive an error message if you use was the argument when you try to write.
- 当你尝试写入时,如果使用
w作为参数,则会收到错误消息
To write the web page to a file, you can use a for loop with the Response object’s iter_content() method. Then you get to specify how many bytes of data you want to write each time, and it will save the memory of your computer.
要将网页写入文件,你可以使用 Response 对象的
iter_content()方法进行循环。然后你可以指定每次写入多少字节的数据,它会保存计算机的内存1
2
3
4
5
6
7
8
9
10
11
12
13import requests
res = requests.get('http://www.gutenberg.org/cache/epub/1112/pg1112.txt')
res.raise_for_status()
length = len(res.text)
print(length)
print(res.text[0:200])
test_file = open('Romeo.txt','wb')
for chunk in res.iter_content(100000):
test_file.write(chunk)
test_file.close()for chunk in res.iter_content(100000)::使用iter_content()方法来循环迭代响应内容的数据块。iter_content()方法返回一个迭代器,每次迭代都会返回指定大小(这里是 100000 字节)的数据块。
Go to your current working directory to see if the file has been created.
- 前往你的当前工作目录,看看文件是否已经创建
You could use thewith open syntax that you have learned and save the hassle of closing the file
- 你可以使用你学过的
with open语法来保存文件,避免手动关闭文件的麻烦
 wechat
wechat alipay
alipay